Nacos源码学习计划-Day04-服务端如何处理客户端的注册请求(下)
ZealSinger 发布于 阅读:383 技术文档
将信息封装为了Instance对象,创建一个对应的Key,将其封装保存在了DataStore这个对象中,并且将key和action封装为一个Pair二元组且使用addTask方法将其放入到阻塞队列中
但其实,我们还是有很多问题
-
整个流程就这样了?没感觉到有啥注册相关的功能啊?
-
为何要添加一个task,这个Task是干啥的?
从目前的分析来看,我们好像并不能体会到Nacos的功能,以及Nacos报告中说到过Nacos服务注册TPS达到13000以上,这么看好像没感受到什么很厉害的设计
所以今天我们就来看看,这背后更深的秘密
异步化设计
敏感的UU应该察觉到了---异步化,我们上面的流程中,直接能看到的处理结果就是封装和装入Task,那么也就是说,只要完成这两两个步骤就算是请求完全处理完毕,也就是能直接Response了,而真正的其余注册的逻辑,其实都放到了任务队列中进行异步的完成,接口响应巨快。
Nacos 服务端会在后台新开启一个单线程异步任务,这个任务在不断地取 BlookingQueue 队列中的内容,把这个队列中的内容取出来之后,再把信息写入到注册表中,从而完成注册
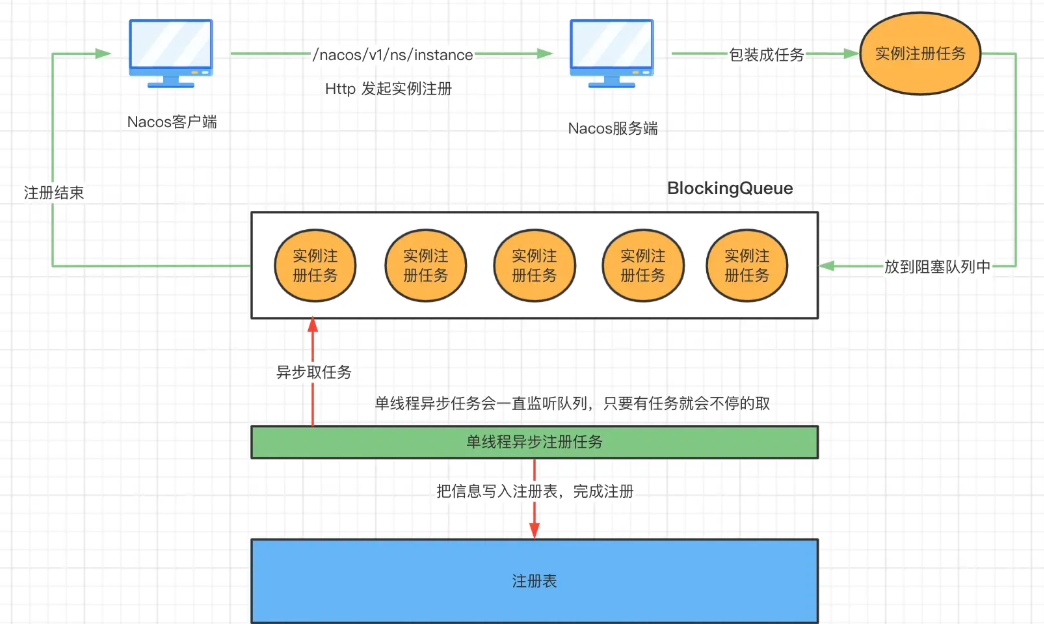
除了能直接响应,整个BlockingQueue阻塞队列类似于MQ的作用,对流量也起到了一定的限流作用 ; BlockingQueue实际上使用的是ArrayBlockingQueue,适合生产者-消费者场景,线程安全并且是单线程处理队列中的任务,也不怕并发问题,读写冲突等等
异步任务和异步队列源码解析
异步任务
我们接着上次的文章进度看,addTask中最后put任务到了task队列中,既然有put那么肯定有take(有进有出),刚好只有一个地方进行的任务的拿取,我们去看看
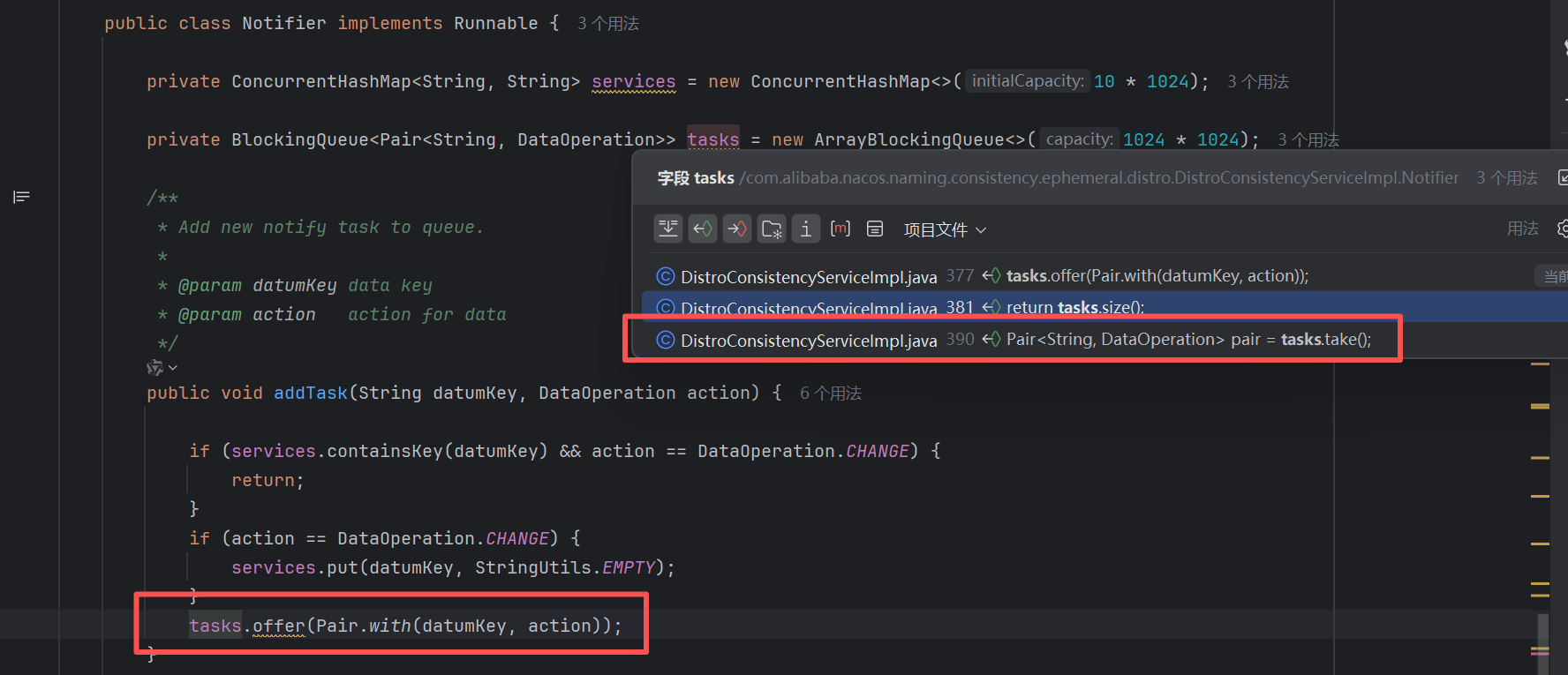
一眼就看到这个take拿取的逻辑处于一个run方法中,就很直接的能知道,Nacos后台异步的方式从队列中拿任务
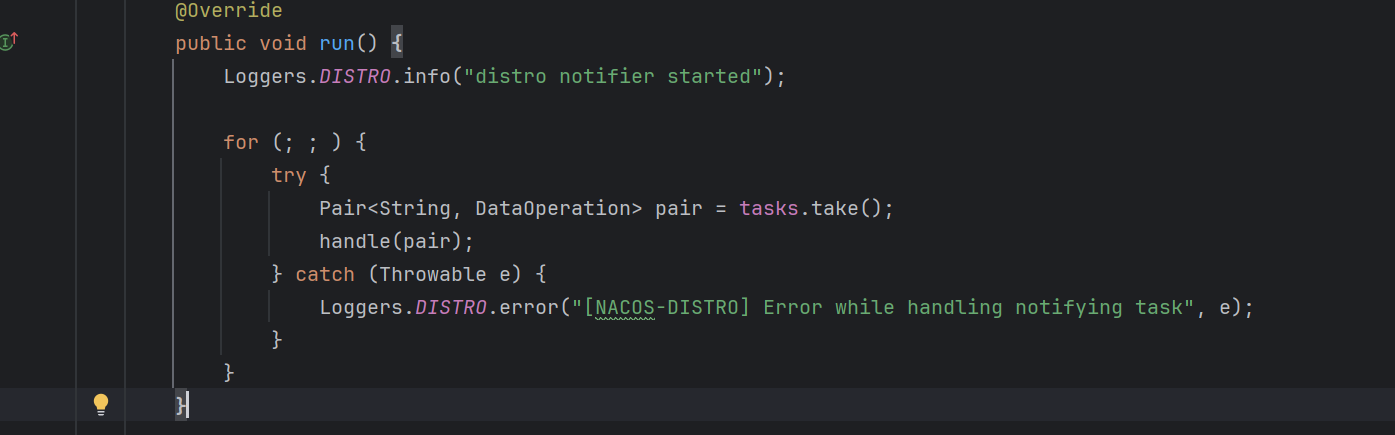
我们先不管run中的逻辑是怎么样的,我们先找找这个任务/这个有线程在哪里创建和启动的
会发现run方法就是Notifier类下的任务,这个类对象我们在上一节中有提到的,而该类的对象创建,是在DistroConsistencyServiceImpl中,Notifier对象作为成员被创建。在这个类中有个@PostConstruct(Spring创建完这个类的Bean就会调用init方法)注解的init方法,该方法中就将Notifier交给了GlobalExecutor即全局线程池执行器,submitDistroNotifyTask方法底层实际上就是创建了一个ScheduledExecutorService线程池对象,让后将任务交给这个线程池执行
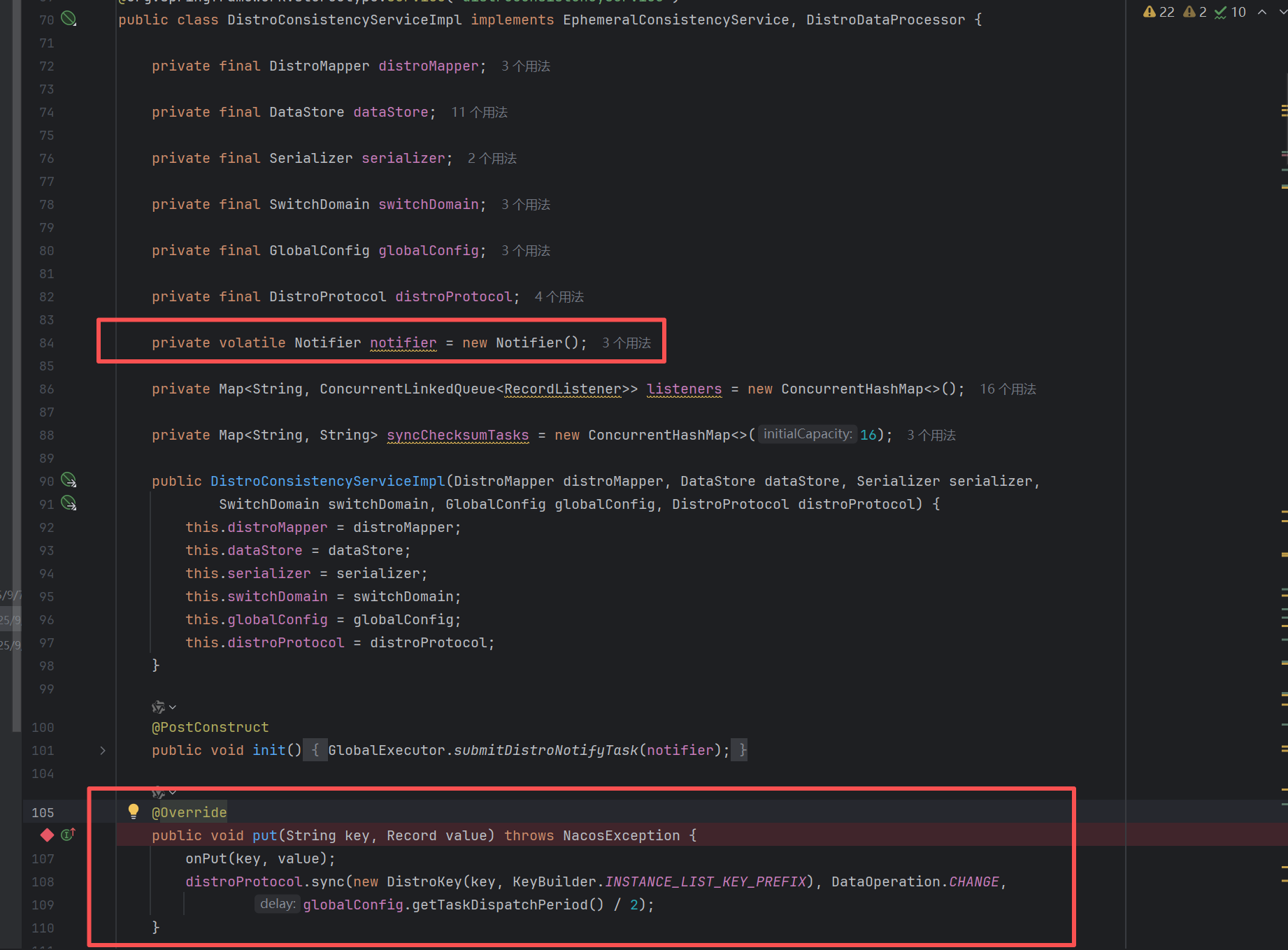
知道什么时候触发的,接下来就可以跳回去看run中的真实的任务逻辑了
public void run() {
Loggers.DISTRO.info("distro notifier started");
// 无限循环 也就说明这个线程一直在从阻塞队列中拿任务
for (; ; ) {
try {
// 从队列中获取任务
Pair<String, DataOperation> pair = tasks.take();
// 处理任务
handle(pair);
} catch (Throwable e) {
Loggers.DISTRO.error("[NACOS-DISTRO] Error while handling notifying task", e);
}
}
}Nacos注册表
在看handle源码之前,我们先来看看Nacos中注册表中的相关概念
看到现在,我们其实可以体会到,整个Nacos中肯定会存在地方存储我们所有的注册实例,在前面所提到的的代码中,都没有所谓的存储过程,那么接下来在handle的逻辑中肯定会有。
不知道大家是否还记得,我们在最开始看Post请求入口的时候,存在一个ServiceManager对象,我们整个注册实例的入口就是在这里进去的。
这个类对象存在一个serviceMap的成员,他在我们之前上篇文章中,其实getService方法中很频繁的出现了,因为和主线无关所以当时没有怎么分析。
现在来看,serviceMap的定义如下,官方注解也标在上面,其实很清楚能知道,这个serviceMap其实就是注册表,其结构就是Map(namespace, Map(group::serviceName, Service))
/**
* Map(namespace, Map(group::serviceName, Service)).
*/
private final Map<String, Map<String, Service>> serviceMap = new ConcurrentHashMap<>();
我们在使用Nacos管理页面的时候,最外层是按照命名空间进行的划分,每个命名空间内的服务又会有不同的group组别标记
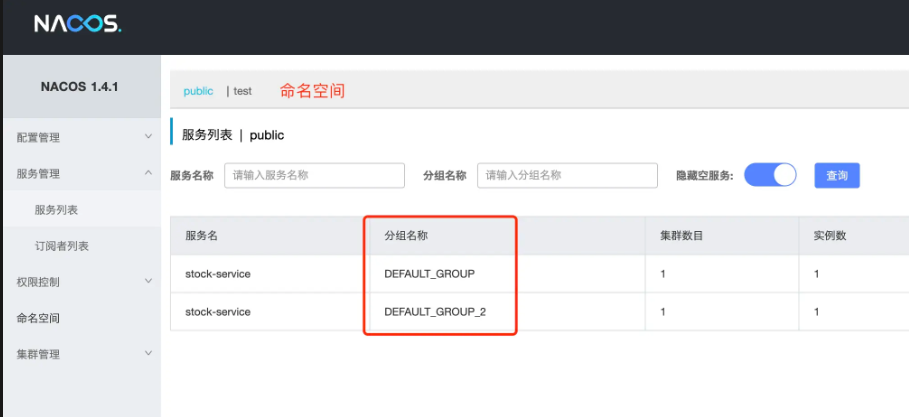
而在进到一个group分组内,又会根据地域cluster的不同划分为多个部分
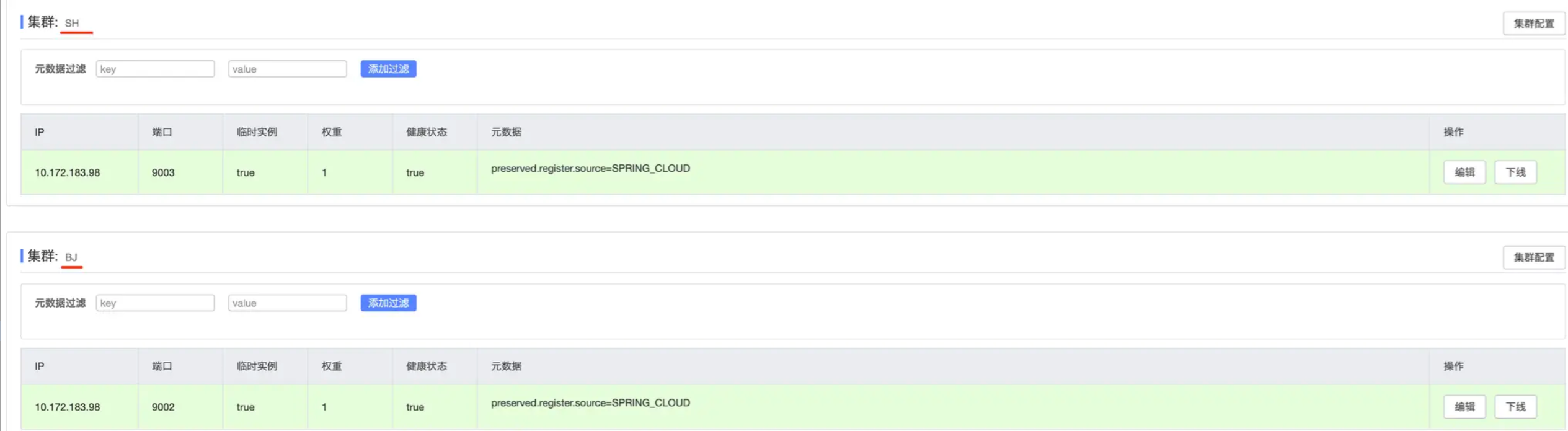
根据这个结构层次,以及我们再来看看serverMap的结构
// Map(namespace, Map(group::serviceName, Service))
Map<String, Map<String, Service>> serviceMap
public class Service extends com.alibaba.nacos.api.naming.pojo.Service implements Record, RecordListener<Instances> {
//..... key为集群名
private Map<String, Cluster> clusterMap = new HashMap<>();
//.....
}
public class Cluster extends com.alibaba.nacos.api.naming.pojo.Cluster implements Cloneable {
//.....
/**
* 持久化实例列表
*/
private Set<Instance> persistentInstances = new HashSet<>();
/**
* 临时实例列表
*/
private Set<Instance> ephemeralInstances = new HashSet<>();
//.....
}
还可以进行debug我们来看看具体注册的时候这个serviceMap的内容
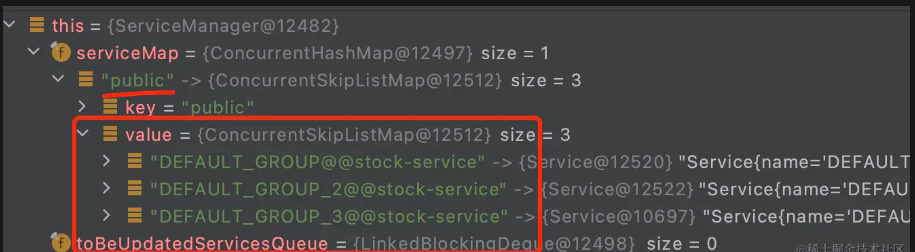
那么我们就能很清楚的知道了整个管理页面和serviceMap之间的对应关系以及整个Nacos注册表的结构。可以看得出Nacos的实例存储结构其实还是蛮复杂的,这个主要是为了适应复杂多变的实际环境
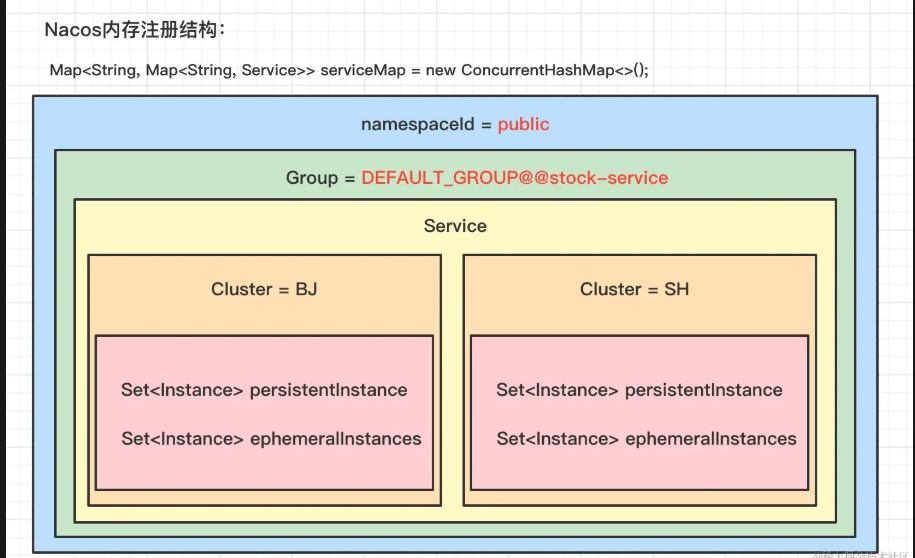
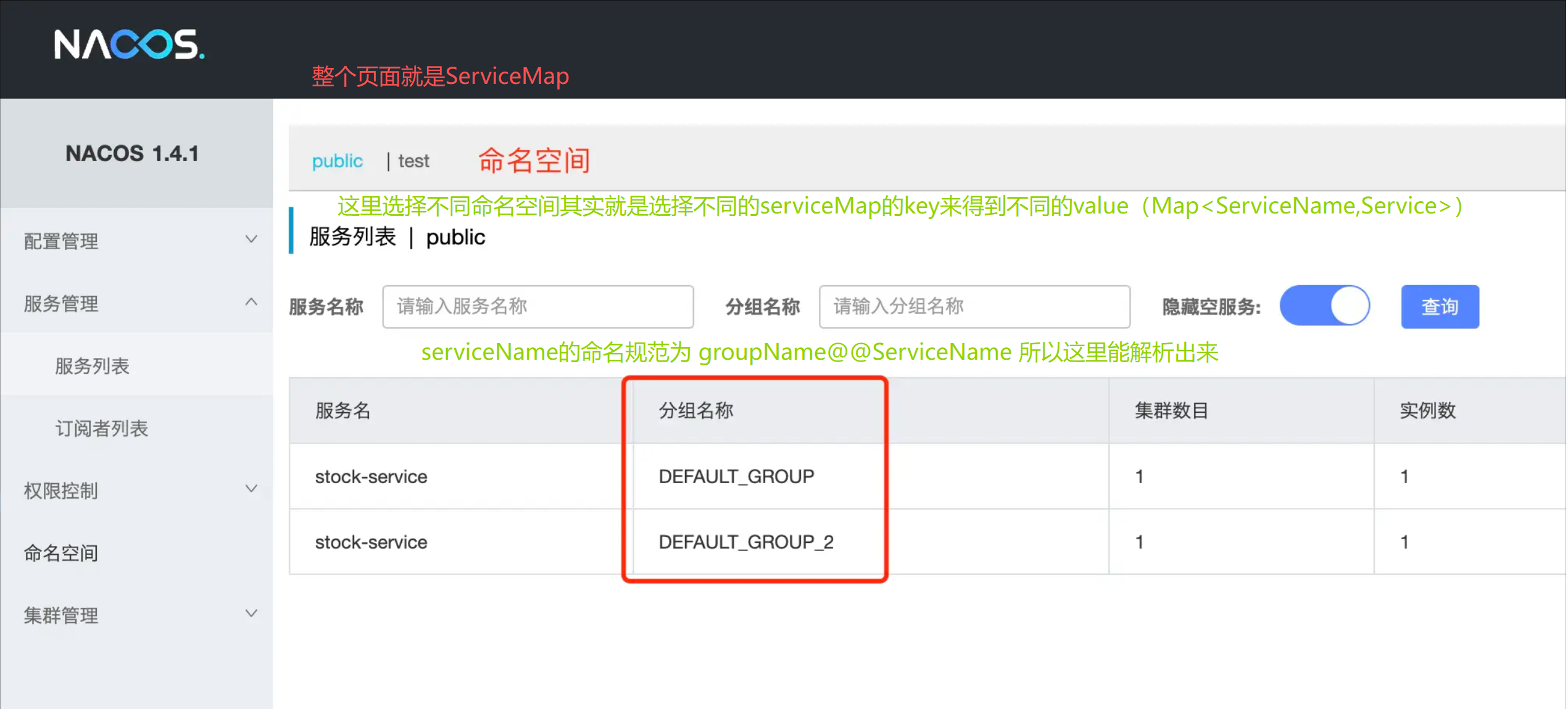
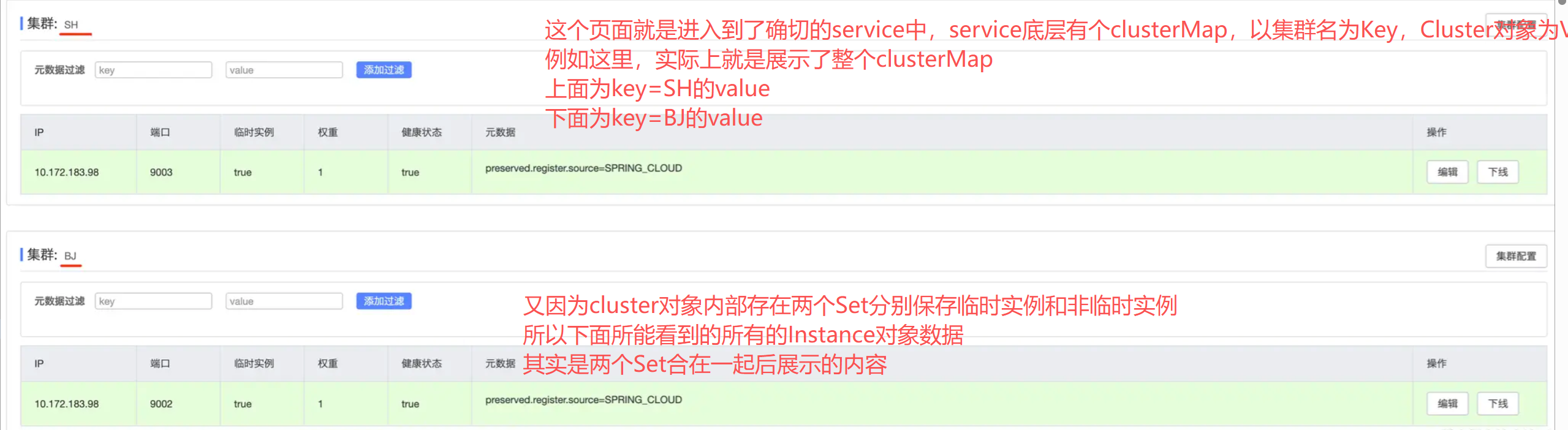
了解完这个存储结构之后,我们可以继续接着看handle方法
handle/onChange
可以看到核心就是handle方法,源码如下
private void handle(Pair<String, DataOperation> pair) {
try {
// 把封装的key和action拿出来
String datumKey = pair.getValue0();
DataOperation action = pair.getValue1();
// 从service中移除对应key的数据 service是个map结构其实也是<key,action>
services.remove(datumKey);
int count = 0;
if (!listeners.containsKey(datumKey)) {
return;
}
// 这里的这些对象啥意思 代表啥 我们暂且先不看
for (RecordListener listener : listeners.get(datumKey)) {
count++;
try {
// 根据之前的代码可以知道 注册的时候 不出意外的话action就是DataOperation.CHANGE
if (action == DataOperation.CHANGE) {
// 所以我们最终走到这个方法中
// 传入key,dataStor中的保存那个map的value值 即Datum<key,value(Instances对象),timestamp(原子Long类型)>
listener.onChange(datumKey, dataStore.get(datumKey).value);
continue;
}
if (action == DataOperation.DELETE) {
listener.onDelete(datumKey);
continue;
}
} catch (Throwable e) {
Loggers.DISTRO.error("[NACOS-DISTRO] error while notifying listener of key: {}", datumKey, e);
}
}
if (Loggers.DISTRO.isDebugEnabled()) {
Loggers.DISTRO
.debug("[NACOS-DISTRO] datum change notified, key: {}, listener count: {}, action: {}",
datumKey, count, action.name());
}
} catch (Throwable e) {
Loggers.DISTRO.error("[NACOS-DISTRO] Error while handling notifying task", e);
}
}
可以看到,核心就是listener.onChange方法,但是该方法有三个实现,我们可以通过Debug的方式最后找到,这里是走到了Service类中的实现,其实现逻辑如下,可以看到,这个逻辑中主要是为当前所有的Instance检测权重数值是否符合要求,然后重要的逻辑在updateIPs方法内
public void onChange(String key, Instances value) throws Exception {
Loggers.SRV_LOG.info("[NACOS-RAFT] datum is changed, key: {}, value: {}", key, value);
// 对每一个Instance中的权重判断是否符合要求,如果不符合要求,会给个默认值
for (Instance instance : value.getInstanceList()) {
if (instance == null) {
// Reject this abnormal instance list:
throw new RuntimeException("got null instance " + key);
}
// 如果设置的权重超过 > 10000.0D,就默认给 10000.0D
if (instance.getWeight() > 10000.0D) {
instance.setWeight(10000.0D);
}
if (instance.getWeight() < 0.01D && instance.getWeight() > 0.0D) {
instance.setWeight(0.01D);
}
}
// 以上也都是分支逻辑
// 真正注册表中的逻辑
updateIPs(value.getInstanceList(), KeyBuilder.matchEphemeralInstanceListKey(key));
recalculateChecksum();
}
addIpAddresses
我们这里来补充一下,Instances这个集合是怎么来的,之前只是知道产生了这个集合,但这个集合的生成过程我们没有去分析,我们找到入口Controller,往下走看到调用addIpAddresses()方法的位置
private List<Instance> addIpAddresses(Service service, boolean ephemeral, Instance... ips) throws NacosException {
// 调用了重载方法
// 第二参数是 action,对应的内容是 add。
return updateIpAddresses(service, UtilsAndCommons.UPDATE_INSTANCE_ACTION_ADD, ephemeral, ips);
}
public List<Instance> updateIpAddresses(Service service, String action, boolean ephemeral, Instance... ips)
throws NacosException {
// 这里 Datum 是从 DataStore 中,通过 key 去获取的,拿取当前DataStore中的key的datum数据
// 假设我们当前是第一个实例注册,方法执行到这里,其实还没有放入到DataStore中,所以获取的应该是null
Datum datum = consistencyService
.get(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), ephemeral));
// ephemeral = true ,true就是表示临时实例列表
// 获取当前service下全部的临时实例列表,从内存注册表中拿。
List<Instance> currentIPs = service.allIPs(ephemeral);
// 创建两个新对象 用于合并旧数据的容器
// currentInstances (Map): 以IP地址为Key,Instance对象为Value。方便快速通过IP查找实例
//currentInstanceIds (Set): 存储所有现有实例的唯一ID。用于为新实例生成不重复的ID
Map<String, Instance> currentInstances = new HashMap<>(currentIPs.size());
Set<String> currentInstanceIds = Sets.newHashSet();
// 遍历全部的临时实例,如果是第一个实例注册,currentIPs应该是空
for (Instance instance : currentIPs) {
// ip当作key、Instance当作value,放入currentInstances
currentInstances.put(instance.toIpAddr(), instance);
// 把实例唯一编码添加到currentInstanceIds中
currentInstanceIds.add(instance.getInstanceId());
}
// 这里是重点 ****
Map<String, Instance> instanceMap;
if (datum != null && null != datum.value) {
/* 如果不为空 把之前的实例信息,则说明非首次注册,添加到instanceMap当中 --- 关键点
这里调用了setValid方法,这是保证旧实例不丢失的核心。
setValid方法的作用:它会将从分布式存储中获取的权威实例列表(datum.value)与当前内存中的实例列表(currentInstances)进行比对。
为什么要比对?:因为分布式存储中的数据是最终一致的,可能略有延迟。currentInstances可能已经包含了最新的、但还未同步到所有节点的健康实例信息(比如刚被健康检查器标记为健康的实例)。
setValid的逻辑:遍历权威数据中的每个实例,并用内存中最新实例信息(如果存在)去更新它(例如更新它的健康状态、元数据等),然后放入instanceMap。如果内存中没有,则直接使用权威数据中的实例。
最终效果:instanceMap现在包含了所有旧实例的最新状态。它成为了接下来进行“新增”或“移除”操作的基准数据集。
*/
instanceMap = setValid(((Instances) datum.value).getInstanceList(), currentInstances);
} else {
// 第一次注册,则创建一个空的 Map
instanceMap = new HashMap<>(ips.length);
}
// 在实例注册的时候,ips 参数只有一个元素,就是 新增的 Instance 对象
for (Instance instance : ips) {
// 如果之前的集群 Map 中没有,先创建一个新的 Cluster 对象
if (!service.getClusterMap().containsKey(instance.getClusterName())) {
Cluster cluster = new Cluster(instance.getClusterName(), service);
cluster.init();
service.getClusterMap().put(instance.getClusterName(), cluster);
Loggers.SRV_LOG
.warn("cluster: {} not found, ip: {}, will create new cluster with default configuration.",
instance.getClusterName(), instance.toJson());
}
// 判断 action 是不是 remove,很明显我们这里传入进来的是 add
if (UtilsAndCommons.UPDATE_INSTANCE_ACTION_REMOVE.equals(action)) {
instanceMap.remove(instance.getDatumKey());
} else {
// 所以代码会走到这里来
// 第一次走这里,instanceMap 是个空的 Map,所以 get 会为 null
Instance oldInstance = instanceMap.get(instance.getDatumKey());
/*
如果oldInstance存在,说明这是旧实例的重新注册(比如客户端心跳重发)。则使用旧实例的ID(instance.setInstanceId(oldInstance.getInstanceId())),这保证了实例ID的稳定性。
如果oldInstance不存在,说明是全新的实例。则为其生成一个全新的、不与当前任何实例ID冲突的ID(instance.generateInstanceId(currentInstanceIds)
*/
if (oldInstance != null) {
instance.setInstanceId(oldInstance.getInstanceId());
} else {
instance.setInstanceId(instance.generateInstanceId(currentInstanceIds));
}
// 关键的在这里
// 看上面标记的重点部分,instanceMap 会有两种情况
// 第一种情况:第一次创建 instanceMap 对应一个空 Map,然后把新增加的 isntance 实例放进去
// 第二种情况:不是第一次创建,instanceMap 会包含之前所创建的 Instance 对象
instanceMap.put(instance.getDatumKey(), instance);
}
}
// 最后 instanceMap 里面肯定会包含 新注册的 Instance 实例
// 并且如果不是第一次注册,里面会包含了 之前 Instance 实例信息
return new ArrayList<>(instanceMap.values());
}
updateIps
弄清楚了怎么获取到的所有的实例集合,就可以继续看注册逻辑了
下面这部分的主要逻辑就是:对传入进来的 Instance 进行归类,最后把分好类的 Instance 对象,根据 Cluster 分类,对每一个 Cluster 中的实例列表进行修改,重点在于后面的updateIps方法,里面体现了写时复制Copy-On-Write的思想
// 这里 instances 实例列表 通过上述对addIpAddresses方法的分析 就知道里面就包含了新实例对象
// ephemeral 为 ture,临时实例
public void updateIPs(Collection<Instance> instances, boolean ephemeral) {
// clusterMap 对应集群的Map
Map<String, List<Instance>> ipMap = new HashMap<>(clusterMap.size());
// 把集群名字都放入到ipMap里面,value是一个空的ArrayList
for (String clusterName : clusterMap.keySet()) {
ipMap.put(clusterName, new ArrayList<>());
}
// 遍历全部的Instance,这里之前讲过,这个List<Instance> 包含了之前已经注册过的实例,和新注册的实例对象
// 这里的主要作用就是把相同集群下的 instance 进行分类
for (Instance instance : instances) {
try {
if (instance == null) {
Loggers.SRV_LOG.error("[NACOS-DOM] received malformed ip: null");
continue;
}
// 判断客户端传过来的是 Instance 中,是否有设置 ClusterName
if (StringUtils.isEmpty(instance.getClusterName())) {
// 如果没有,即没有显示的指定集群名,就给ClusterName赋值为 DEFAULT
instance.setClusterName(UtilsAndCommons.DEFAULT_CLUSTER_NAME);
}
// 判断之前是否存在对应的 ClusterName,如果没有则需要创建新的 Cluster 对象
if (!clusterMap.containsKey(instance.getClusterName())) {
Loggers.SRV_LOG
.warn("cluster: {} not found, ip: {}, will create new cluster with default configuration.",
instance.getClusterName(), instance.toJson());
// 创建新的集群对象
Cluster cluster = new Cluster(instance.getClusterName(), this);
cluster.init();
// 放入到集群 clusterMap 当中
getClusterMap().put(instance.getClusterName(), cluster);
}
// 通过集群名字,从 ipMap 里面取,创建ipMap的时候其value都是空的arrayList 所以这里的clusterIPs也是空的ArrayList
List<Instance> clusterIPs = ipMap.get(instance.getClusterName());
// 只有是新创建集群名字,这里才会为空,之前老的集群名字,在方法一开始里面都 value 赋值了 new ArrayList对象
// 某个集群名完全是最新的 还没有创建对应的集群对象就有可能为null
if (clusterIPs == null) {
clusterIPs = new LinkedList<>();
ipMap.put(instance.getClusterName(), clusterIPs);
}
// 把对应集群下的instance,添加进去
clusterIPs.add(instance);
} catch (Exception e) {
Loggers.SRV_LOG.error("[NACOS-DOM] failed to process ip: " + instance, e);
}
}
// 分好类之后,针对每一个 ClusterName ,写入到注册表中
for (Map.Entry<String, List<Instance>> entry : ipMap.entrySet()) {
// entryIPs 已经是根据ClusterName分好组的实例列表
List<Instance> entryIPs = entry.getValue();
// 根据写时复制,对每一个 Cluster 对象修改注册表 *** 重点
// updateIps 则是 写时复制 的体现
clusterMap.get(entry.getKey()).updateIps(entryIPs, ephemeral);
}
setLastModifiedMillis(System.currentTimeMillis());
getPushService().serviceChanged(this);
StringBuilder stringBuilder = new StringBuilder();
for (Instance instance : allIPs()) {
stringBuilder.append(instance.toIpAddr()).append("_").append(instance.isHealthy()).append(",");
}
Loggers.EVT_LOG.info("[IP-UPDATED] namespace: {}, service: {}, ips: {}", getNamespaceId(), getName(),
stringBuilder.toString());
}
updateIps方法源代码如下,在这里体现了写时复制的思想,全程都没有对之前注册表中的数据进行操作,而是先拿出来,最后直接把新的数据替换过去,这样就完成了注册表修改,也就是一个复制操作+整体替换
/**
* Update instance list.
*
* @param ips instance list
* @param ephemeral whether these instances are ephemeral
*/
// 这里入参就是更新后的实例列表
public void updateIps(List<Instance> ips, boolean ephemeral) {
// 先判断是否是临时实例
// ephemeralInstances 临时实例
// persistentInstances 持久化实例
// 把对应数据先拿出来,放入到 新创建的 toUpdateInstances 集合中
Set<Instance> toUpdateInstances = ephemeral ? ephemeralInstances : persistentInstances;
// 先把老的实例列表复制一份 , 先复制一份新的
HashMap<String, Instance> oldIpMap = new HashMap<>(toUpdateInstances.size());
for (Instance ip : toUpdateInstances) {
oldIpMap.put(ip.getDatumKey(), ip);
}
// 中间不重要的代码略,主要是对 oldIpMap 一些操作,其中也包括了集群节点同步,这里小册第二部分会详细讲解
// 最后把传入进来的实例列表,重新初始化一个 HaseSet,赋值给toUpdateInstances
toUpdateInstances = new HashSet<>(ips);
// 判断是否是临时实例
if (ephemeral) {
// 直接把之前的实例列表替换成新的
ephemeralInstances = toUpdateInstances;
} else {
persistentInstances = toUpdateInstances;
}
}
总结
主要讲解了 Nacos 内存注册表结构,可以看出 Nacos 注册表使用方式还是很灵活的,可以通过命名空间、分组、集群来进行实例的区分,具体使用可以根据公司业务场景来定。
分析了 Nacos 实例注册异步任务中,是如何利用“写时复制”来完成注册表的修改(其实就是遍历集合的时候不能对集合进行修改,即fast-fail机制,解决这个机制的办法就是Copy-On-Write)在这个过程中,还回到之前的分支代码,addIpAddresses 方法做了什么。
本章的相关流程如下
文章标题:Nacos源码学习计划-Day04-服务端如何处理客户端的注册请求(下)
文章链接:https://zealsinger.xyz/?post=29
本站所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议,转载请注明来自ZealSinger !
如果觉得文章对您有用,请随意打赏。
您的支持是我们继续创作的动力!

微信扫一扫

支付宝扫一扫