Akka-Actor模型-解决高并发的终极方案-入门篇(四)
ZealSinger 发布于 阅读:1021 技术文档
首先,在Akka中的所谓“监督”的关系为:监督者将任务委派给下属进行完成,如果失败了,下属必须会汇报给监督者,监督者也必须根据指定的策略进行处理
监督者策略
常见的策略有如下四个
-
Resume and keeping
恢复下属,保持其积累的内部状态
-
Restart and clearing
重启下属,清除其积累的内部状态
-
Stop
永久停止下属
-
Escalate the failure,thereby failing itself
将失败上报给父监管者(当前监管者无法处理)
-
自定义策略
在思考监督者策略的时候,要将整个监督结构看作是一个子父联系结构,这也就比较好理解Escalate这种策略,一个Actor可以是另外一个Actor的监督者,同时自然也可以是另外一个Actor的被监督者,在这个思想下就需要知道,前三种Resume,Restart,Stop策略,在执行的时候,会对其所有的下属进行重启或者停止
当父resume,stop,restart的时候,其子类也会跟着进行对应的操作
配置策略主要是通过重写supervisorStrategy方法,该配置成功之后,全局无法动态修改,因为他会成为组成actor的一部分
样例代码如下
// Main.kt
fun main(args: Array<String>) {
val system = ActorSystem.create("ClusterSystem")
val firstActor = system.actorOf(
Props.create(ClusterMasterActor::class.java),
"firstActor"
)
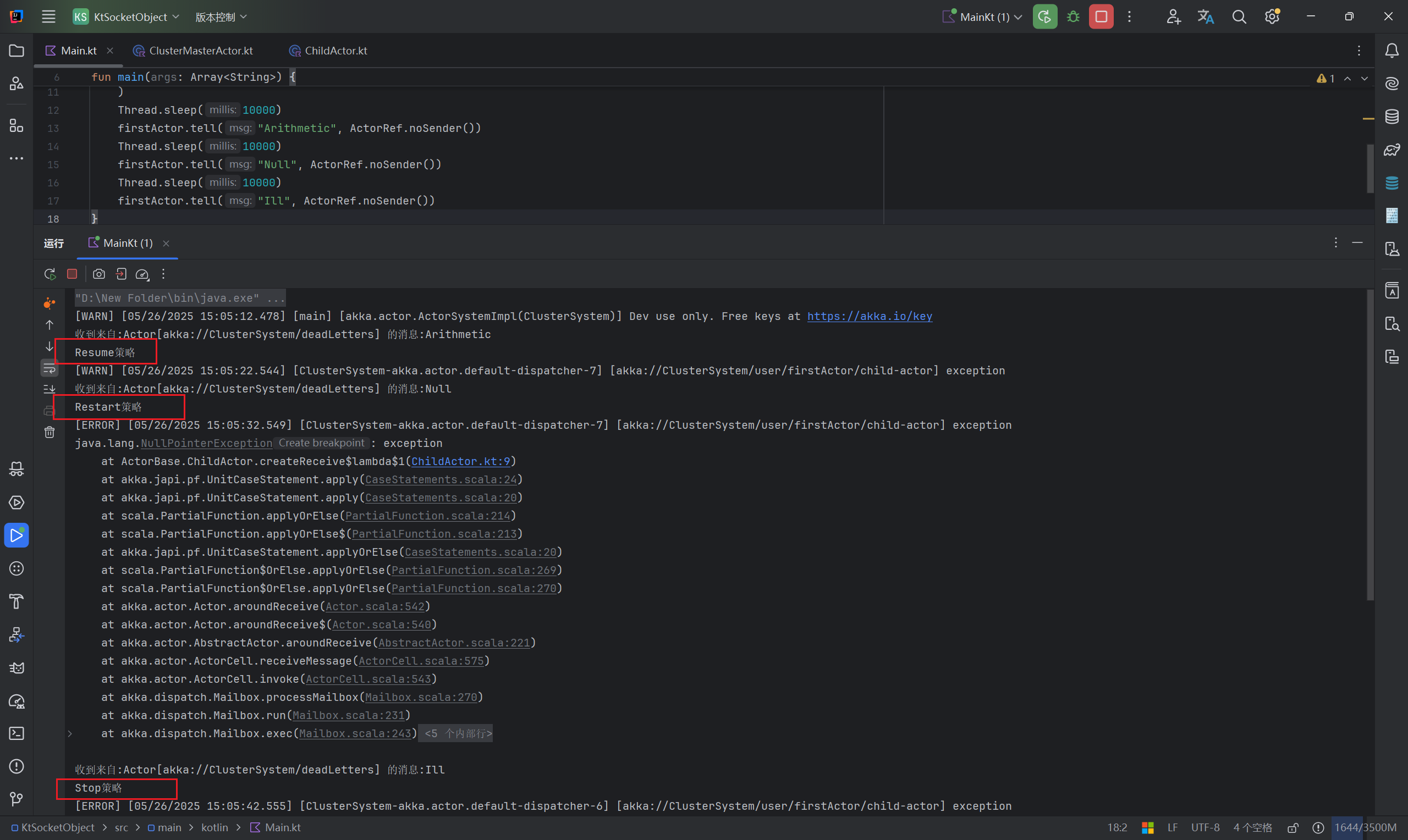
// 分别发送三种消息 测试三种策略
Thread.sleep(10000)
firstActor.tell("Arithmetic", ActorRef.noSender())
Thread.sleep(10000)
firstActor.tell("Null", ActorRef.noSender())
Thread.sleep(10000)
firstActor.tell("Ill", ActorRef.noSender())
}
// ClusterMasterActor.kt
class ClusterMasterActor :AbstractActor() {
val childActor = context.actorOf(Props.create(ChildActor::class.java), "child-actor")
// 通过重写supervisorStrategy方法 来实现对于不同异常的处理策略
override fun supervisorStrategy(): SupervisorStrategy {
// 返回值为OneForOneStrategy 标识只会影响出错误的子Actor及其子树 比较合理
// 还有一种为AllForOneStrategy 标识会影响子Actor及其同级Actor以及两者的子树 需要注意别误伤正常子Actor
return OneForOneStrategy(
// 第一个参数maxNrOfRetries代表允许最大重试/重启次数
3,
// 第二个参数withTimeRange代表时间窗口 统计异常次数的时间范围(1 分钟)
// 这两个参数
Duration.create(1, TimeUnit.MINUTES),
// 第三个参数为DeciderBuilder构造器 构造对于不同的异常的处理策略
DeciderBuilder.match(ArithmeticException::class.java) {
println("Resume策略")
resume()
}
.match(NullPointerException::class.java) {
println("Restart策略")
restart()
}
.match(IllegalArgumentException::class.java) {
println("Stop策略")
stop()
}
.matchAny { escalate() }
.build()
)
}
override fun createReceive(): Receive {
return receiveBuilder()
.match(String::class.java,{
println("收到来自:${context().sender()} 的消息:${it}")
childActor.tell(it,self)
})
.matchAny {
println("other message: {${it}}")
}
.build()
}
}
// ChildActor.kt
class ChildActor: AbstractActor() {
// 对于不同的信息抛出不同的异常
override fun createReceive(): Receive {
return receiveBuilder()
.matchEquals("Arithmetic",{throw ArithmeticException("exception")})
.matchEquals("Null",{throw NullPointerException("exception")})
.matchEquals("Ill",{throw IllegalArgumentException("exception")})
.build()
}
}
运行效果如下,可以看到根据不同的异常执行了不同的监督策略
对于OneForOneStrategydee 相关参数设置,如下补充方便理解
1. maxNrOfRetries = -1 且 withinTimeRange = Duration.Inf()
含义:
maxNrOfRetries = -1:允许无限次重启。
withinTimeRange = Duration.Inf():时间窗口为无限长(即不限制时间范围)。
行为:
子 Actor 会无限次重启,永不停止,无论失败多少次。
适用场景:
需要子 Actor 始终存活,即使频繁失败(例如关键服务必须持续尝试恢复)。
2. maxNrOfRetries = 非负数 且 withinTimeRange = Duration.Inf()
含义:
maxNrOfRetries = 非负数(例如 3):允许最多重启 3 次。
withinTimeRange = Duration.Inf():时间窗口为无限长。
行为:
一旦重启次数超过 maxNrOfRetries,子 Actor 将被永久停止。
由于时间窗口是无限的,重启计数器永远不会重置。
示例:
若 maxNrOfRetries = 3,子 Actor 在第 4 次失败时会被停止。
3. maxNrOfRetries = -1 且 withinTimeRange = 非无限时间
含义:
maxNrOfRetries = -1:Akka 会将此值隐式转换为 1。
withinTimeRange = 非无限时间(例如 1分钟):时间窗口为 1 分钟。
行为:
子 Actor 在 1 分钟内最多重启 1 次,超过后会被停止。
原因:
Akka 不允许在有限时间窗口内设置无限次重启(maxNrOfRetries = -1 会被视为 1)。
4. maxNrOfRetries = 非负数 且 withinTimeRange = 非无限时间
含义:
maxNrOfRetries = 非负数(例如 3):允许最多重启 3 次。
withinTimeRange = 非无限时间(例如 1分钟):时间窗口为 1 分钟。
行为:
在 1 分钟内,子 Actor 最多重启 3 次。
若在 1 分钟内失败超过 3 次,子 Actor 会被停止。
若超过 1 分钟后再次失败,重启计数器会重置为 0。
示例:
子 Actor 在 0:00、0:30、0:50 失败 3 次(均在 1 分钟内)→ 第 3 次失败后被停止。
子 Actor 在 0:00、0:30、1:10 失败 3 次(最后一次在时间窗口外)→ 计数器重置,允许继续重启。
当我们没有设置监督策略或者抛出的异常处于设置的监督策略之外的时候,默认会应用Escalate策略,该策略覆盖了常见的异常
如果是ActorInitializationException异常,则直接停止失败的子Actor
如果是ActorKilledException异常,则直接停止失败的子Actor
如果是DeathPactException异常,则直接停止失败的子Actor
如果是Exception则重启失败的子Actor
如果是其他的则向上抛给父Actor(到父Actor中匹配,如果父Actor中还是没有,也会继续向上抛,最终可能抛到/user甚至/ 上 从而停止整个服务)
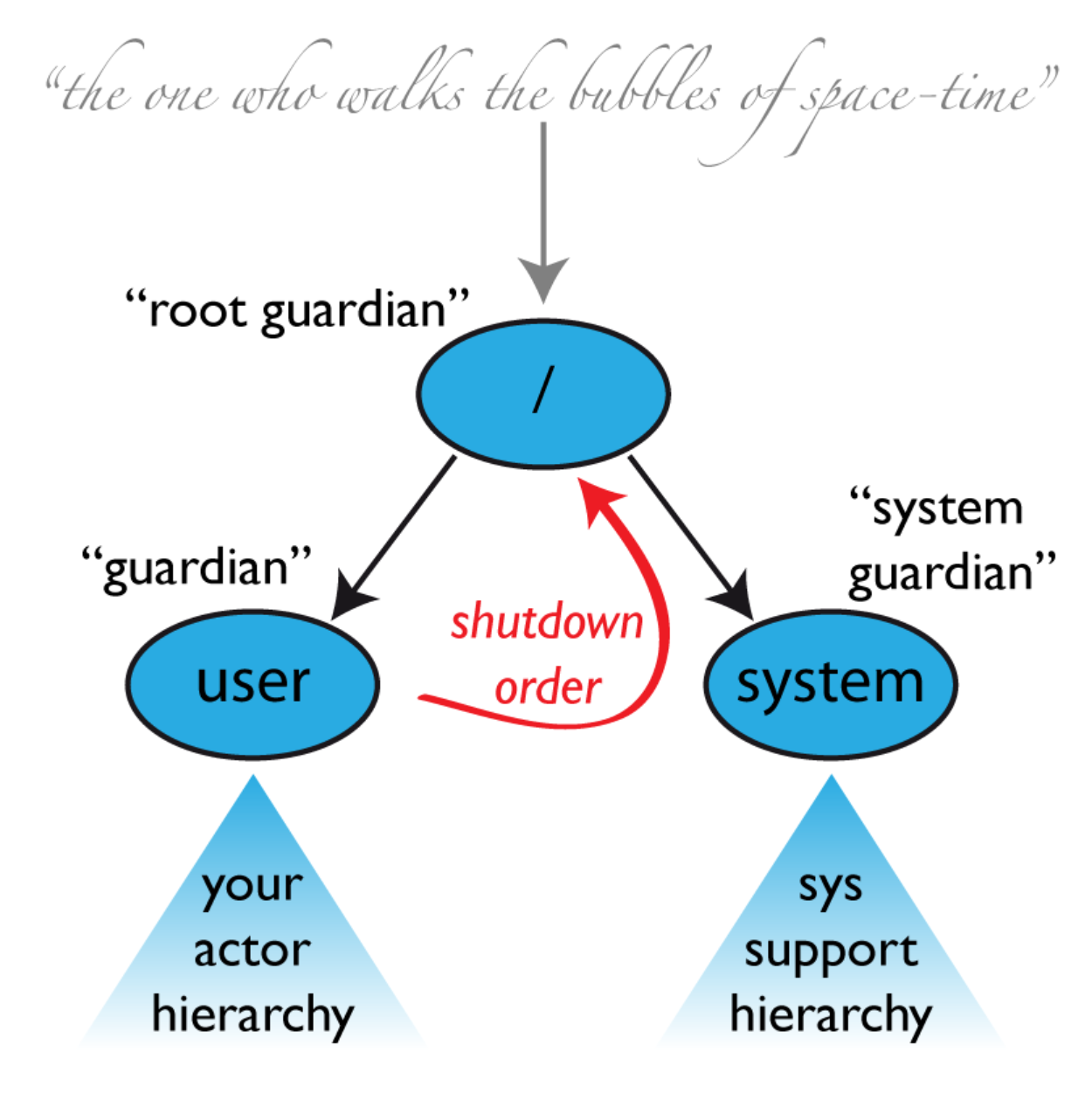
顶级监管
对于任何一个Actor系统,起码会存在三个Actor,Actor会自动创建三个顶级Actor,分别是 / /user /system
/ 根监管
最顶级的监管,类似于Java中的Object和Kotlin中的Any的地位,用于维护整个Actor系统,当期重启or停止将会递归处理系统中的所有Actor
/ user 用户监管
交互最频繁的 actor 可能是所有用户创建的 actor 的父级,即名为 “/user” 。使用 system.actorOf() 创建的 Actor 是此 Actor 的子项。这意味着,当此Actor终止时,系统中的所有正常参与者也将关闭。从 Akka 2.1 开始,可以通过配置文件 akka.actor.guardian-supervisor-strategy 自定义配置Actor对于子Actor的监管策略,当然也可以在/user中配置escalate策略,将其抛给/ 根监管
实际上,我们在讲述actorSelectation的时候就应该接触到了/user了,可以看到我们创建的所有的Actor其实都是在/user的层级之下
val actorSelection = context.actorSelection("akka://ClusterSystem@127.0.0.1:2551/user/firstActor")
/ system 系统监管
系统监管是一个特殊监管,其主要作用是监管/user用户监管的,保证系统的稳定性和有序关闭
所谓有序关闭,就是Actor的关闭顺序,例如AKKA中的日志系统,其实本质上是通过一个日志Actor进行,那么在关闭整个系统的时候,日志Actor需要收集所有的信息,自然需要最后一个关闭,所以这个需要收到/system的控制(通过监听Terminated消息和一定的控制手段)
日志级别设置
故障只要不是被升级抛给父Actor,其余的在本Actor处理的都会被记录,记录的日志级别也还是通过重写SupervisorStrategy,通过Decider进行配置(只有Java版是因为对应的withLogLevel方法在Kotlin没找到对应的..需要再找找资料看看)
public class MySupervisor extends AbstractActor {
private static SupervisorStrategy strategy =
new OneForOneStrategy(
10,
Duration.create("1 minute"),
// Decider with log level
DeciderBuilder
.match(ArithmeticException.class, e ->
SupervisorStrategy.restart().withLogLevel(Logging.WarningLevel()))
.match(NullPointerException.class, e ->
SupervisorStrategy.resume().withLogLevel(Logging.InfoLevel()))
.matchAny(o ->
SupervisorStrategy.escalate().withLogLevel(Logging.ErrorLevel()))
.build()
);
public SupervisorStrategy supervisorStrategy() {
return strategy;
}
public Receive createReceive() {
return receiveBuilder().build();
}
}
延迟重启
当子Actor出现问题的时候,很多时候是进行重启,但是我们知道,一般情况下是需要一定的恢复时间的,也就是按照常理而言我们应该是隔一段时间进行重启即延迟重启而不是让其不断地不间隔地重启
我们在创建子Actor的时候需要对应的Props对象,我们可以利用BackoffIots.onFailure()方法,构建一个支持延迟重启的Props,从而构建可以延迟重启的Actor
// Main.kt
fun main(args: Array<String>) {
val system = ActorSystem.create("ClusterSystem")
val firstActor = system.actorOf(
Props.create(ClusterMasterActor::class.java),
"firstActor"
)
firstActor.tell("Null", ActorRef.noSender()) // 激活ClusterMasterActor
}
// ClusterMasterActor.kt
class ClusterMasterActor :AbstractActor() {
var childActor:ActorRef? = null
init {
val props = BackoffSupervisor.props(
BackoffOpts.onFailure(
Props.create(ChildActor::class.java),
"child-actor",
Duration.create(5, TimeUnit.SECONDS), // 5s最小延迟重启 对应方法参数minBackOf
Duration.create(10, TimeUnit.SECONDS), // 10s最大延迟重启 对应方法参数maxBackoff
// 会按照5-10依次增加重启间隔且有20%的随机波动
0.2 // 增加一部分额外方差 防止雪崩
)
)
childActor = context.actorOf(props)
}
override fun supervisorStrategy(): SupervisorStrategy {
return OneForOneStrategy(
3,
Duration.create(1, TimeUnit.MINUTES),
DeciderBuilder.match(ArithmeticException::class.java) {
println("Resume策略")
resume()
}
.match(NullPointerException::class.java) {
println("Restart策略")
restart()
}
.match(IllegalArgumentException::class.java) {
println("Stop策略")
stop()
}
.matchAny {
println("Escalate策略")
escalate()
}
.build()
)
}
override fun createReceive(): Receive {
return receiveBuilder()
.match(String::class.java,{
println("收到来自:${context().sender()} 的消息:${it}")
childActor?.tell(it,self)
})
.matchAny {
println("other message: {${it}}")
}
.build()
}
}
// ChildActor.kt
class ChildActor: AbstractActor() {
override fun preStart() {
println("重启时间${System.currentTimeMillis()}") // 记录时间方便对比观察
super.preStart()
}
override fun createReceive(): Receive {
return receiveBuilder()
.matchEquals("Arithmetic",{throw ArithmeticException("exception")})
.matchEquals("Null",{
println("抛出异常时间${System.currentTimeMillis()}")
throw NullPointerException("exception")
})
.matchEquals("Ill",{throw IllegalArgumentException("exception")})
.build()
}
}
如下观察,差不多相差了5000ms,和设定是一样的
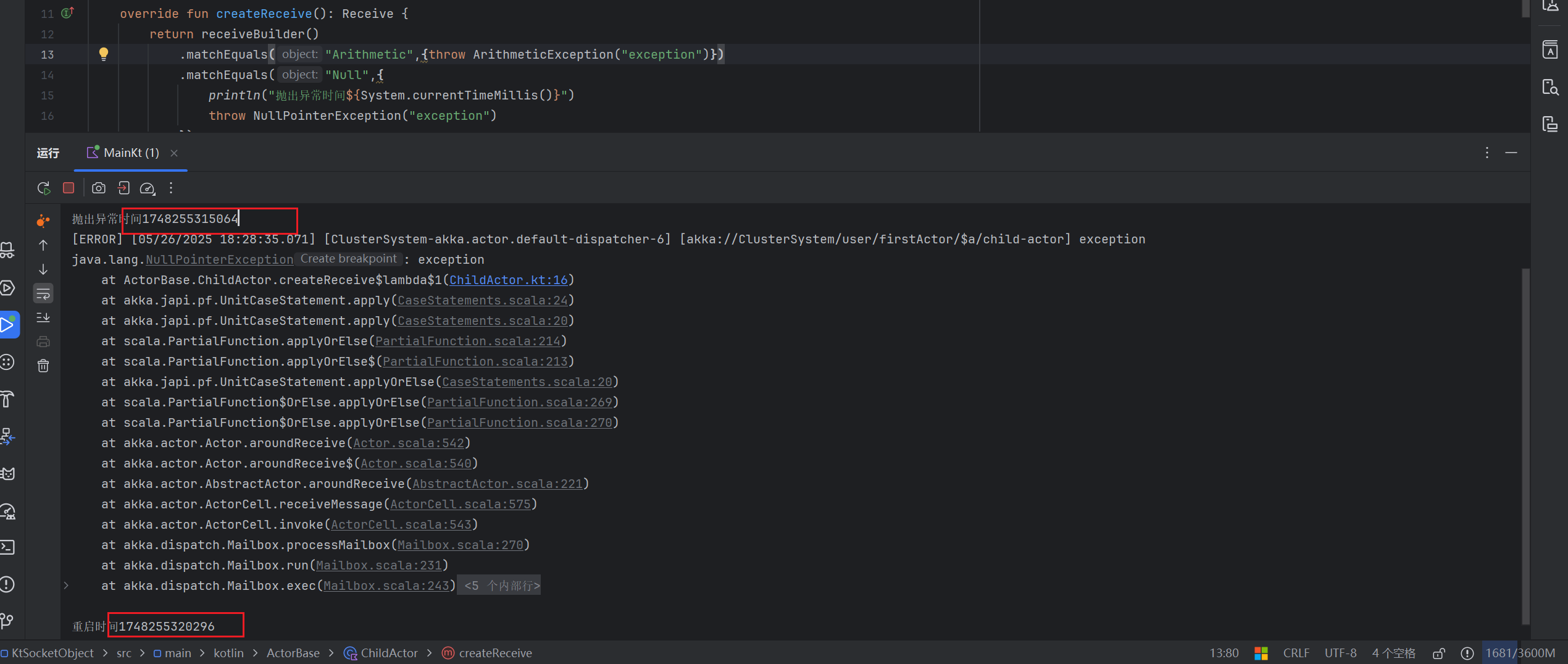
上述情况下,是在子Actor确实是需要restart的时候,进行的延迟重启,同样的,在我们子Actor不是restart而是需要Stop的情况下,我们可能希望在Stop的一段时间后能尝试自动重启
为了满足这个需求,存在一个BackoffOpts.onStop() 用于配置当子Actor停止的时候的相关重启策略
BackoffOpts.onStop(
Props.create(ChildActor::class.java),
"child-actor",
Duration.create(5, TimeUnit.SECONDS), // minBackoff = 5s
Duration.create(10, TimeUnit.SECONDS), // maxBackoff = 10s
0.2 // 随机因子
)
onStop和onFailure通用配置
两者有一些通配的设置
重置退避计时 (withAutoReset / withManualReset)
withAutoReset(默认)
如果子 Actor 在 minBackoff 时间内无故障,退避计时自动重置。
例如:若子 Actor 稳定运行 3 秒,后续故障的重试间隔会从最小退避时间重新开始。
withManualReset
子 Actor 需显式发送 BackoffSupervisor.Reset 消息给父监督器来重置退避。
适用场景:当子 Actor 完成关键任务后主动通知监督器重置状态。
监督策略 (withSupervisionStrategy)
默认策略
使用 SupervisorStrategy.defaultDecider:遇到异常时停止并重启子 Actor。
自定义策略
可覆盖 OneForOneStrategy,定义更精细的异常处理逻辑(如仅处理特定异常)。
c. 最大重试次数 (withMaxNrOfRetries)
默认值 -1:无限重试。
设置后,超过次数则永久停止子 Actor 和监督器。
注意:更换监督策略会重置此参数。
d. 停止时的回复 (withReplyWhileStopped)
默认行为:子 Actor 停止期间收到的消息会被转发到死信信箱。
启用后:监督器直接回复发送方(如返回错误消息)。
val supervisor = BackoffSupervisor.props(
BackoffOpts
.onStop( // 使用 BackoffOnStopOptions
childProps, // 子 Actor 的 Props
childName = "myEcho",
minBackoff = 3.seconds, // 最小退避时间
maxBackoff = 30.seconds, // 最大退避时间
randomFactor = 0.2 // 增加随机性避免同时重试
)
.withManualReset() // 子 Actor 需发送 Reset 来重置退避
.withMaxNrOfRetries(-1)
)
Dispatcher的使用
AKKA中可以通过Dispatcher来实现对线程池的使用,Dispatcher 实现 接口,因此可用于运行 调用
配置Dispatcher
AKKA是给Props配置Dispatcher,在配置之前我们需要创建和定义Dispatcher,通过配置文件的方式进行定义
akka {
actor {
# 自定义 Dispatcher 配置
dispatchers {
# 高优先级任务 Dispatcher
high-priority-dispatcher { // 自定义dispatcher的name
type = "Dispatcher"
executor = "fork-join-executor" // 指定线程池类型 默认一般为forJoinExecutor
fork-join-executor {
parallelism-min = 2
parallelism-factor = 2.0
parallelism-max = 8
}
throughput = 100
}
# 阻塞 I/O 任务 Dispatcher
blocking-io-dispatcher {
type = "Dispatcher"
executor = "thread-pool-executor"
thread-pool-executor {
fixed-pool-size = 16 // fixed-pool-size 表示线程池的 固定大小,即核心线程数和最大线程数被设为相同的值(均为 16),且线程池不会动态扩容或缩容
}
}
}
}
}
对于线程池的还有一些别的参数可以设置
akka.actor.dispatchers {
my-blocking-dispatcher {
type = Dispatcher
executor = "thread-pool-executor"
thread-pool-executor {
fixed-pool-size = 16
keep-alive-time = 30s
allow-core-timeout = on // 是否允许核心线程数超时终止
task-queue-type = array // 务队列类型,决定任务排队策略。可选值:linked:无界队列(默认),可能导致内存溢出。
array:有界队列,需配合 task-queue-size 使用。
task-queue-size = 1000 // task队列的最大容量
}
throughput = 100 # 单个线程每次处理的最大消息数
}
}
然后是将这个配置中的Dispatcher配置给对应的Actor
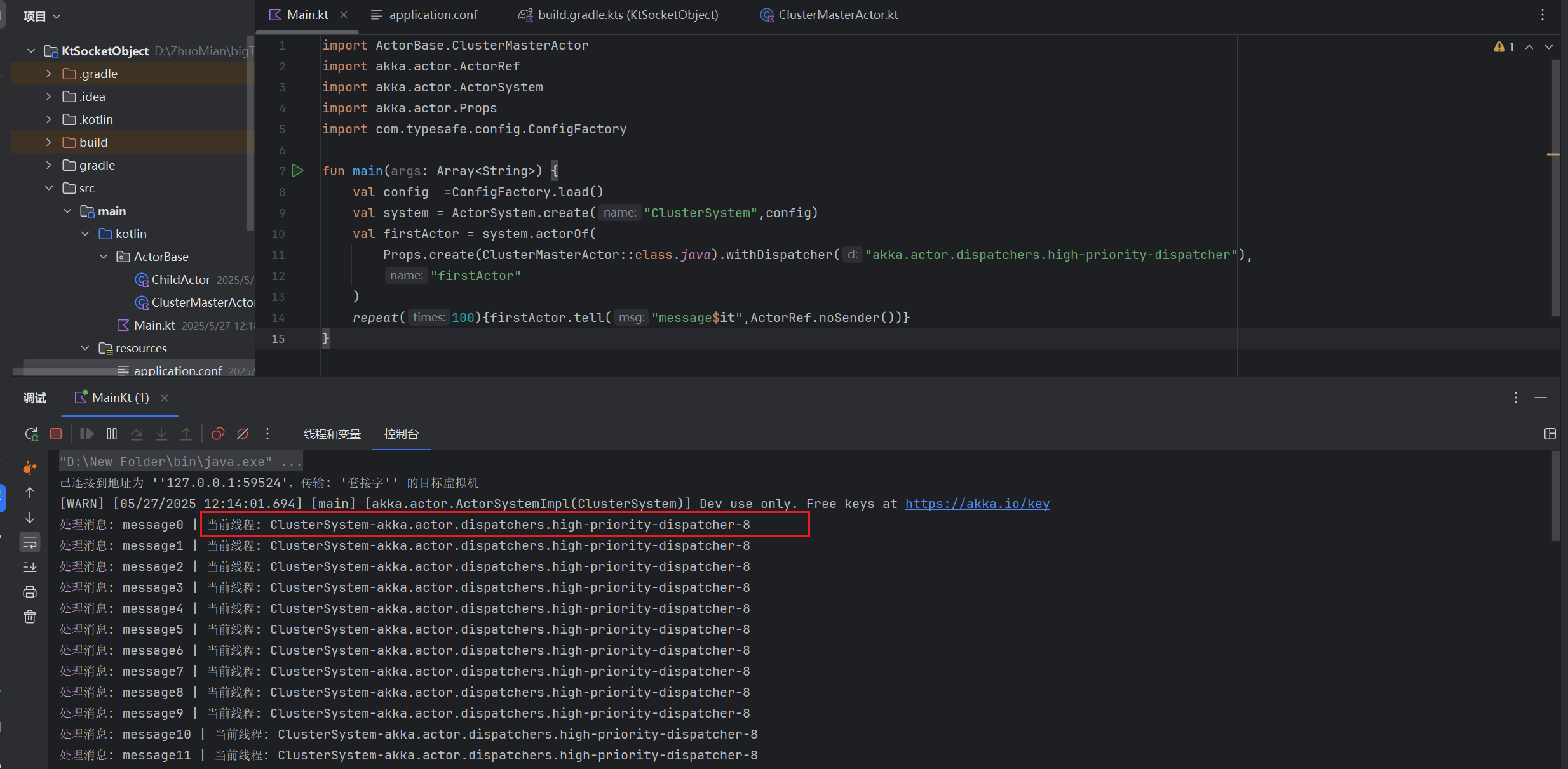
fun main(args: Array<String>) {
val config =ConfigFactory.load()
val system = ActorSystem.create("ClusterSystem",config)
val firstActor = system.actorOf(
Props.create(ClusterMasterActor::class.java).withDispatcher("akka.actor.dispatchers.high-priority-dispatcher"),
"firstActor"
) // 通过Propos.create().withDispatcher()进行配置
repeat(100){firstActor.tell("message$it",ActorRef.noSender())} // 这里是利用repeat批量发送100条信息,方便待会儿测试
}
输出如下 从控制台上可以看出来 用的是我们的high-priority-dispatcher(等后面学了AKKA HTTP之后 可以通过内置对外暴露的接口查看所有的配置的Dispatcher)
MailBox的使用
MailBox即邮箱,每一个Actor都有一个专属于自己的邮箱,保存着所有的要发到该Actor的消息
Deafult MailBox默认邮箱
当没有任何指定和配置的时候,就是默认邮箱,本质上是一个无边界的链表结构,底层其实就是ConcurrentLinkedQueue即同步链表队列,即能有线程安全的往从队头放入新的消息,Actor也能线程安全的从队尾拿取消息
相比较之下,有个SingleConsumerOnlyUnboundedMailbox是一个更加高效的邮箱,基本可以替换默认邮箱,但是不能和BalancingDispatcher一起使用,通过如下配置可以替换默认的邮箱
akka.actor.default-mailbox {
mailbox-type = "akka.dispatch.SingleConsumerOnlyUnboundedMailbox"
}
修改Actor的Message Queue类型
如果想要修改某个Actor的Message Queue类型,即要求其使用某种类型的消息队列,可以通过让该实现RequiresMessageQueue<T>接口,然后将type参数映射到配置中即可
// 实现接口 指定要该Actor的MailBox使用BoundedMessageQueueSemantics类型
class ClusterMasterActor :AbstractActor(), RequiresMessageQueue<BoundedMessageQueueSemantics> {
....
}
然后将该类型写入到配置文件中
akka {
actor {
# 定义有界邮箱配置
mailbox {
bounded-mailbox {
mailbox-type = "akka.dispatch.NonBlockingBoundedMailbox"
mailbox-capacity = 1000
mailbox-push-timeout-time = 10s # 可选:队列满时等待超时时间
}
}
# 将语义接口映射到完整邮箱配置路径
mailbox.requirements {
"akka.dispatch.BoundedMessageQueueSemantics" = akka.actor.mailbox.bounded-mailbox
}
}
}
修改Dispatcher的Message Queue类型
对于Dispatcher的Message Queue类型的修改,主要就是在配置文件中(之前提到过的配置Dispatcher的配置文件)添加maxilbox-requirement属性即可配置
my-dispatcher {
mailbox-requirement = org.example.MyInterface
}
自定义邮箱
-
MyPrioMailbox继承自UnboundedStablePriorityMailbox,这是一个 Akka 内置的无界优先级邮箱类,支持通过PriorityGenerator定义消息优先级。 -
构造函数 接受
ActorSystem.Settings和Config参数,这是 Akka 通过反射实例化邮箱时必需的签名。 -
重写 gen 函数逻辑:通过返回整数值定义消息的优先级(数值越低,优先级越高):
-
"highpriority"→ 0(最高优先级) -
默认消息 → 1(中等优先级)
-
"lowpriority"→ 2(最低优先级) -
PoisonPill→ 3(最后处理)
-
-
关键点:
PoisonPill的优先级设置为 3,确保其在队列中所有其他消息处理完毕后才被处理,符合 Akka 的语义(Actor 应在终止前完成所有任务)
static class MyPrioMailbox extends UnboundedStablePriorityMailbox {
// needed for reflective instantiation
public MyPrioMailbox(ActorSystem.Settings settings, Config config) {
// Create a new PriorityGenerator, lower prio means more important
super(
new PriorityGenerator() {
@Override
public int gen(Object message) {
if (message.equals("highpriority"))
return 0; // 'highpriority messages should be treated first if possible
else if (message.equals("lowpriority"))
return 2; // 'lowpriority messages should be treated last if possible
else if (message.equals(PoisonPill.getInstance()))
return 3; // PoisonPill when no other left
else return 1; // By default they go between high and low prio
}
});
}
}
文章标题:Akka-Actor模型-解决高并发的终极方案-入门篇(四)
文章链接:https://zealsinger.xyz/?post=18
本站所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议,转载请注明来自ZealSinger !
如果觉得文章对您有用,请随意打赏。
您的支持是我们继续创作的动力!

微信扫一扫

支付宝扫一扫