Nacos源码学习计划-Day09-集群-新增微服务实例
ZealSinger 发布于 阅读:204 技术文档
这一段的实现逻辑在Nacos1.4中设计比较麻烦,所以本次的内容可能会比较绕。这里采用总分的方式,也就是我们先直接上一个总结设计描述,然后再查看每个部分的源码
新增实例整体逻辑描述
Nacos 是利用了双层内存队列 + 异步任务来实现的。
第一层:利用了 ConcurrentHashMap 作为任务的存储容器,Nacos 会把新增节点信息包装成一个 DistroDelayTask 任务,放入到 tasks 的 Map 当中,在后台有一个 DistroTaskEngineHolder Bean 对象,在这个 Bean 对象中,有一个属性叫做 DistroDelayTaskExecuteEngine,在这个属性的构造方法里面,会开启一个异步任务来从 ConcurrentHashMap 中进行取任务。
第二层:利用了 BlockingQueue 作为任务的存储容器,会根据参数创建 DistroSyncChangeTask 类型的任务,它是一个线程任务,最终把任务放入到BlockingQueue中去。在 Nacos 后台有一个 InnerWorker 异步任务,它会从队列中取 DistroSyncChangeTask 线程任务,并且调用它的 run 方法来执行。
在 DistroSyncChangeTask 任务中,最后是通过 HTTP 的方式,调用其他集群节点的 API 接口来完成数据同步。
新增实例源码分析
这个肯定要从新增实例的代码中入手,我们继续看到新增实例的Controller
我们之前分析“Nacos服务端如何处理新增实例请求”的时候有分析到,会走到ephemeralConsistencyService的put方法中,我们再来看看这个put方法
public void put(String key, Record value) throws NacosException {
onPut(key, value);
distroProtocol.sync(new DistroKey(key, KeyBuilder.INSTANCE_LIST_KEY_PREFIX), DataOperation.CHANGE,
globalConfig.getTaskDispatchPeriod() / 2);
}之前我们分析单机的新增实例的逻辑,我们只是看了onPut中的相关逻辑,这次我们看一下下面的distroProtocol.sync的相关逻辑
// 这个distroKey是上层传来的,由String key = KeyBuilder.buildInstanceListKey(namespaceId, serviceName, ephemeral);得到一个每个独特实例的包含命名空间+服务名+按照是否为临时实例的不同字符串前缀,得到的唯一Key 和 常量字符串KeyBuilder.INSTANCE_LIST_KEY_PREFIX 一起new出来的DistroKey对象
// action为枚举类DataOperation中的CHANGE
/* delay为全局配置中的taskDispatchPeriod的1/2
@Value("${nacos.naming.distro.taskDispatchPeriod:2000}")
private int taskDispatchPeriod = 2000;
这个数值可以在配置文件中进行配置
*/
public void sync(DistroKey distroKey, DataOperation action, long delay) {
// 遍历除开自身以外的其他集群节点
for (Member each : memberManager.allMembersWithoutSelf()) {
// 包装第一层 distroKey.getResourceKey()为key = KeyBuilder.buildInstanceListKey(namespaceId, serviceName, ephemeral) distroKey.getResourceType()为KeyBuilder.INSTANCE_LIST_KEY_PREFIX
DistroKey distroKeyWithTarget = new DistroKey(distroKey.getResourceKey(), distroKey.getResourceType(),
each.getAddress());
// 包装第二层
DistroDelayTask distroDelayTask = new DistroDelayTask(distroKeyWithTarget, action, delay);
// 添加任务
distroTaskEngineHolder.getDelayTaskExecuteEngine().addTask(distroKeyWithTarget, distroDelayTask);
if (Loggers.DISTRO.isDebugEnabled()) {
Loggers.DISTRO.debug("[DISTRO-SCHEDULE] {} to {}", distroKey, each.getAddress());
}
}
}
可以看到,最后添加任务addTask方法接受了两个参数,分别是distroKeyWithTarget和distroDelayTask,其中前者充当一个Key的作用,后者才是真正的Task任务,来看一下addTask的逻辑,可以看到最后是放到了内部的一个ConcurrentHashMap中
protected final ConcurrentHashMap<Object, AbstractDelayTask> tasks;
public void addTask(Object key, AbstractDelayTask newTask) {
lock.lock();
try {
AbstractDelayTask existTask = tasks.get(key);
if (null != existTask) {
newTask.merge(existTask);
}
// 最后放入到 ConcurrentHashMap 中
tasks.put(key, newTask);
} finally {
lock.unlock();
}
}
我们尝试去找找tasks这个map取任务的逻辑,可以看到在同类下的有个processTasks方法,从命名来看就是和执行任务相关,可以看到这里有相关的可能为执行代码的逻辑,并且在Try代码块中很明显有个retryFailedTask的方法,也就是对于失败任务的重试机制,所以我们可以从上面的getProcessor方法入手,看getProcessor方法可以看到,虽然内部有if分支,但是无论如何都是返回一个NacosTaskProcessor这个接口的实现类去接收taskKey
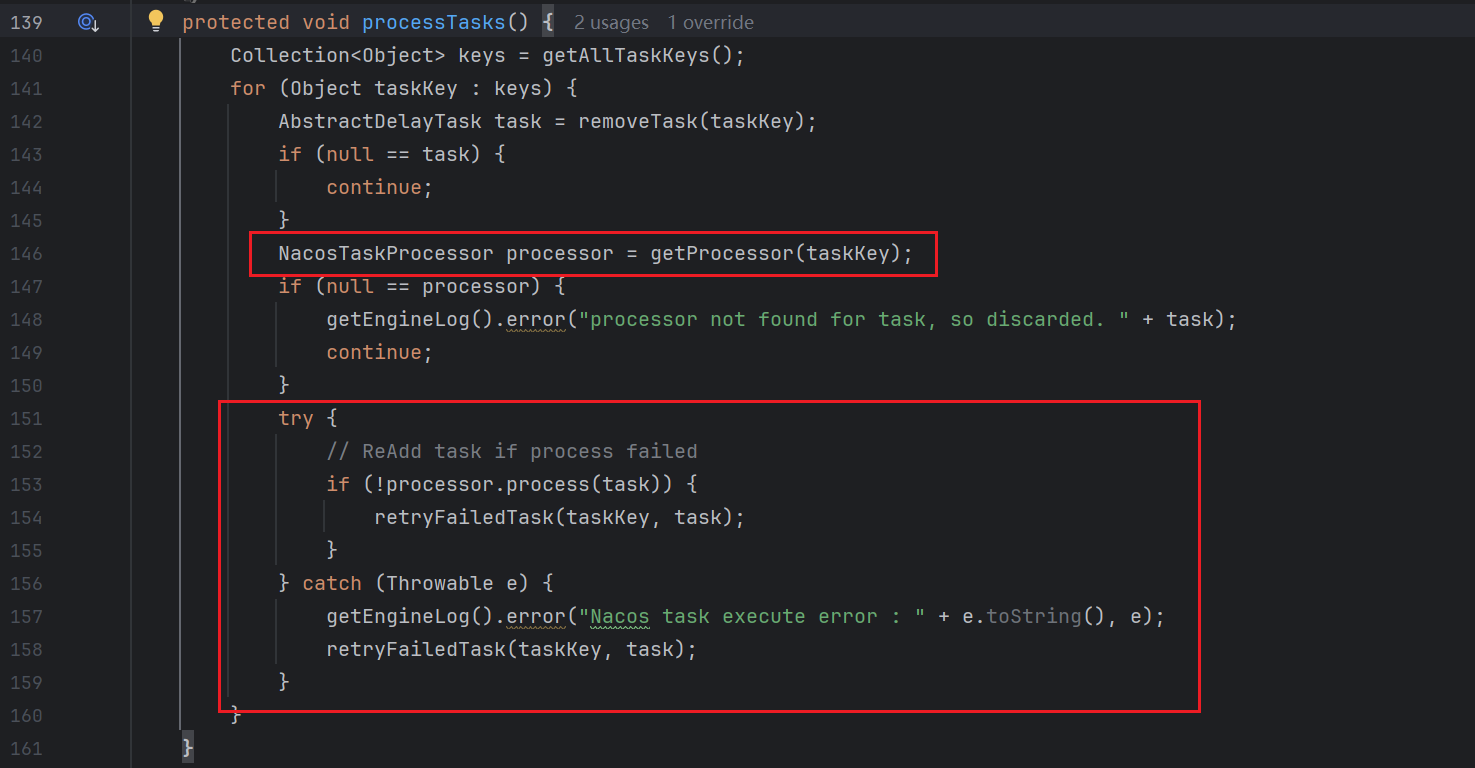
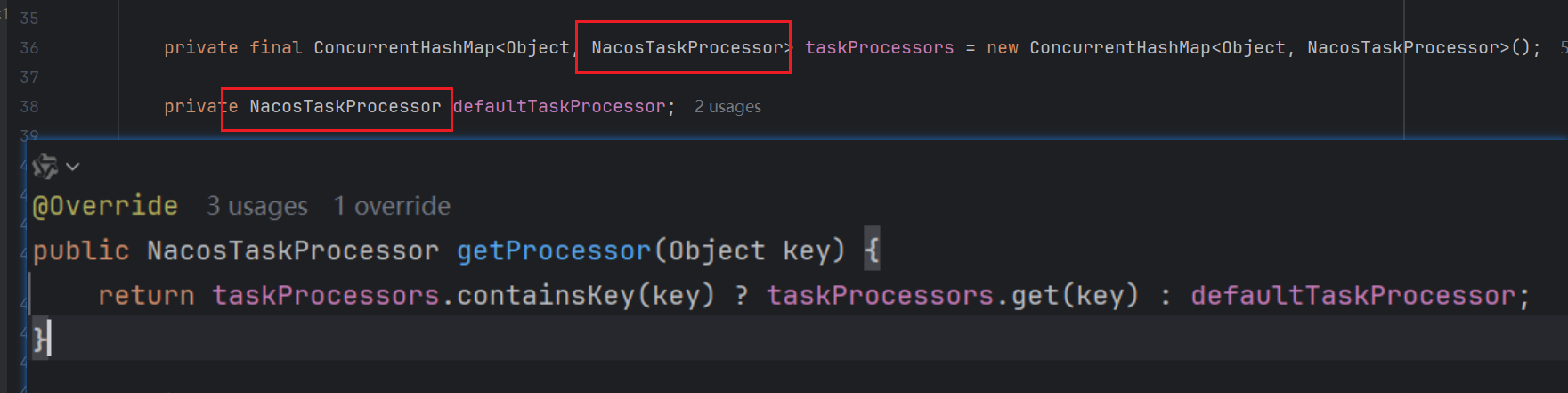
因为我们整个逻辑是从NacosDelayTaskExecuteEngine中进入和分析的,那么这里我们可以从对应的DistroDelayTaskProcessor中查看执行逻辑,可以发现,最终执行task的其实是DistroTaskEngineHolder这个数据类型的成员
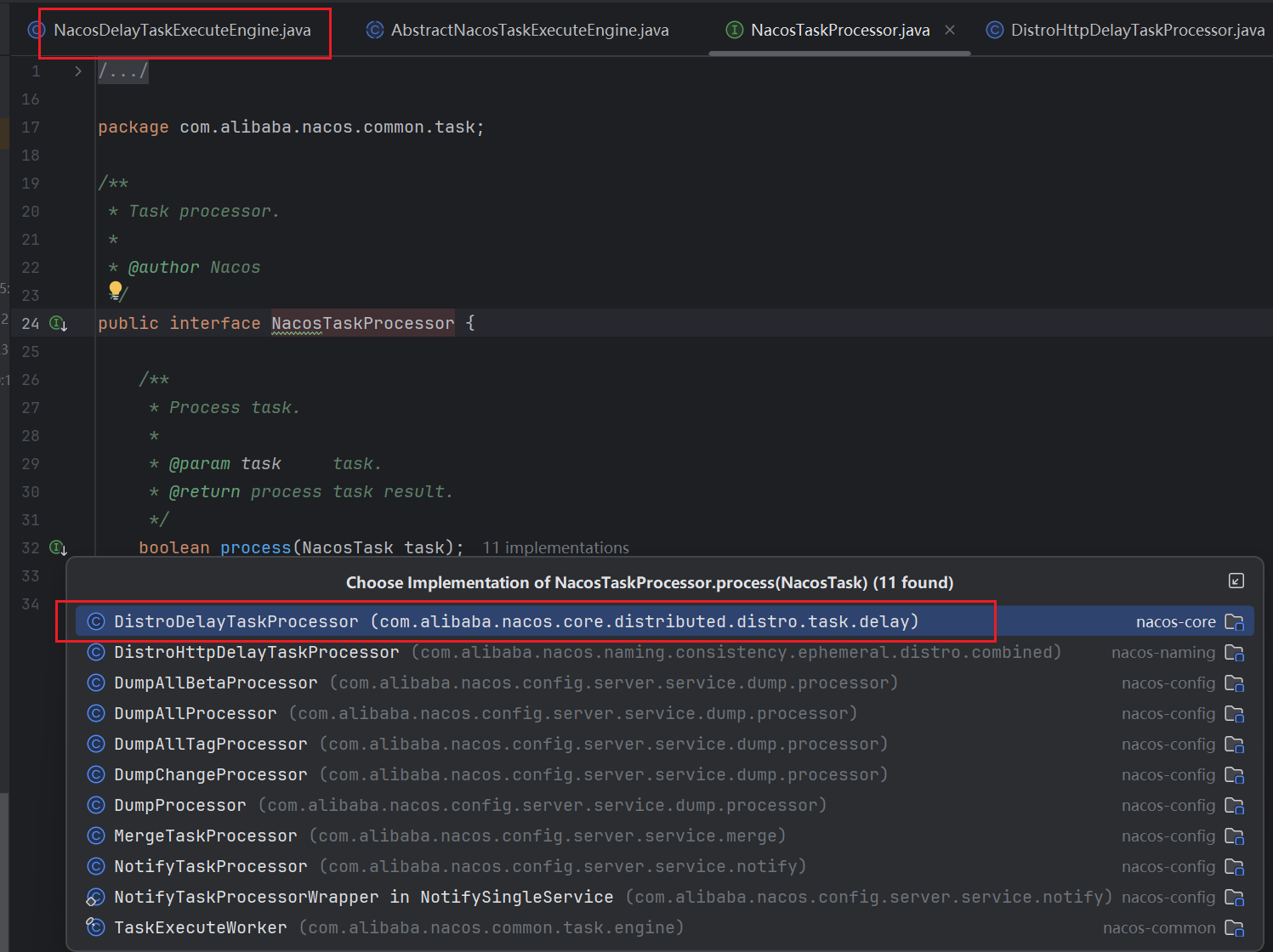
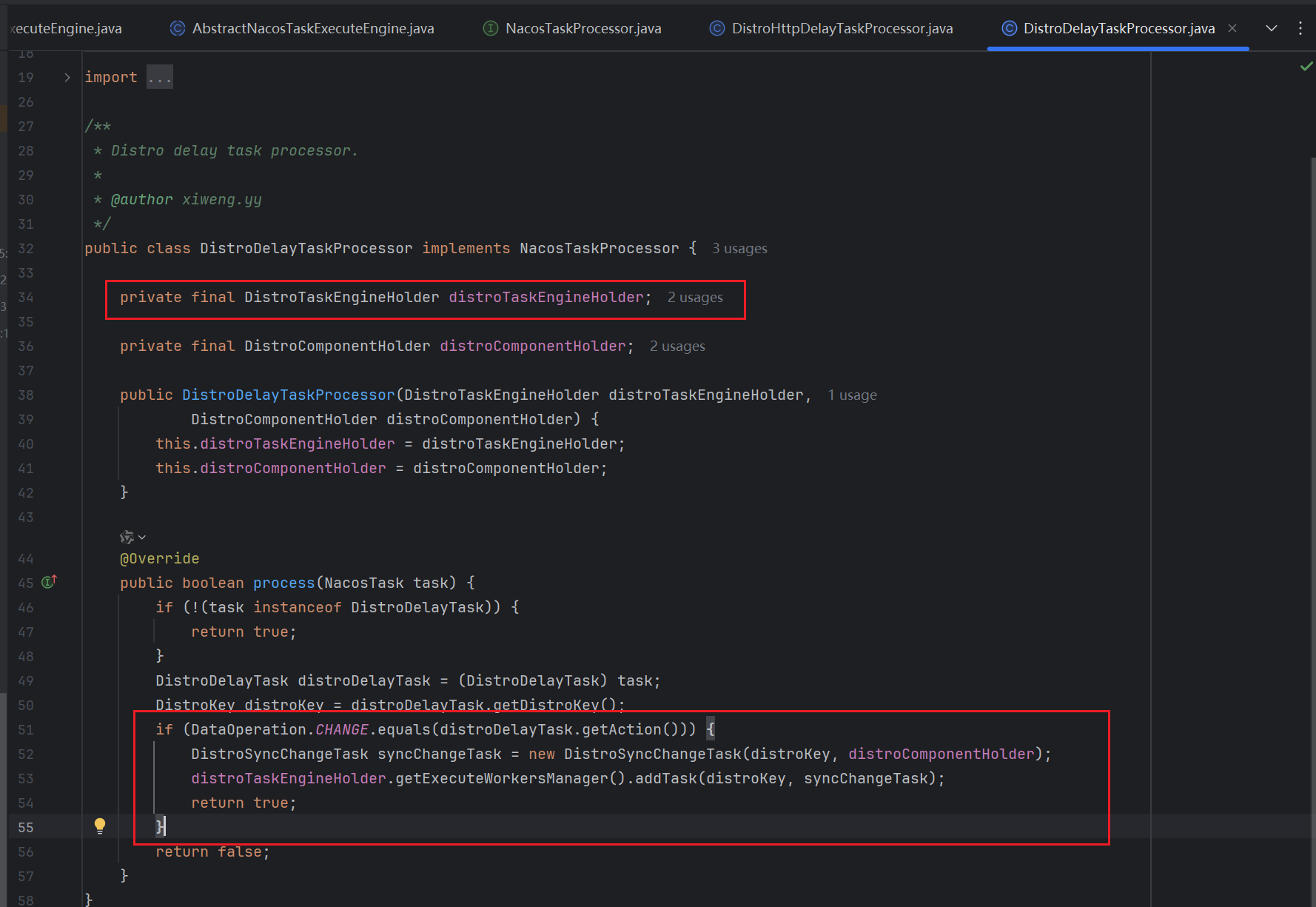
这个 DistroTaskEngineHolder 是个Bean 对象,也就是说会被容器管理自动创建,那么其成员DistroDelayTaskExecuteEngine也会被自动初始化和创建
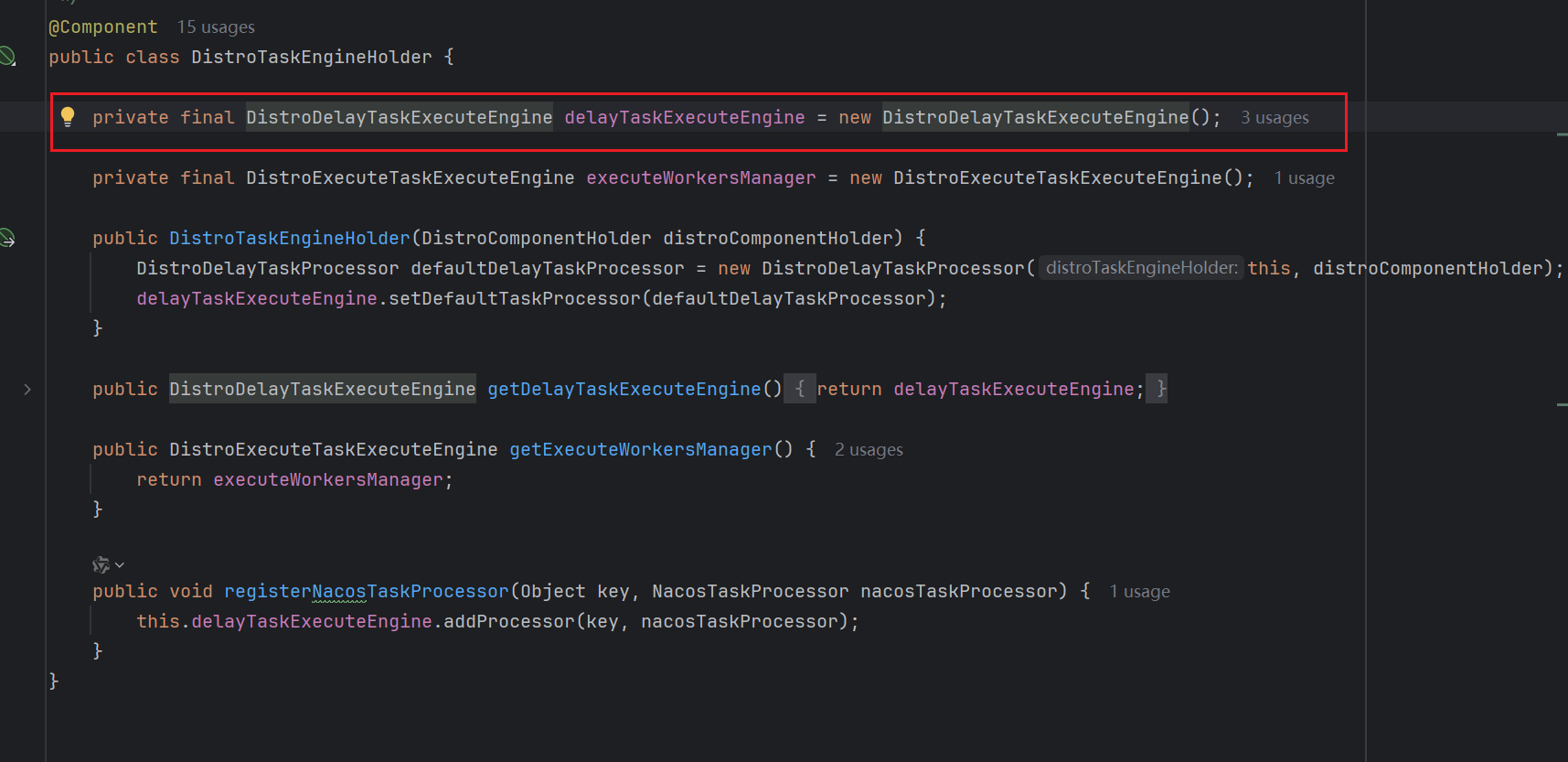
在DistroDelayTaskExecuteEngine 属性类的构造方法中,会去初始化它父类的构造方法,对应的父类是NacosDelayTaskExecuteEngine ,在他父类的初始化逻辑中,就会开启异步任务
public NacosDelayTaskExecuteEngine(String name, int initCapacity, Logger logger, long processInterval) {
super(logger);
tasks = new ConcurrentHashMap<Object, AbstractDelayTask>(initCapacity);
processingExecutor = ExecutorFactory.newSingleScheduledExecutorService(new NameThreadFactory(name));
// 开启延时任务
processingExecutor
.scheduleWithFixedDelay(new ProcessRunnable(), processInterval, processInterval, TimeUnit.MILLISECONDS);
}
可以看到,他执行的任务是第一个参数,即 ProcessRunnable 类型,我们来看看ProcessRunnable 的逻辑,可以发现,起始底层就是我们最初的processTasks
private class ProcessRunnable implements Runnable {
public void run() {
try {
// 核心方法
processTasks();
} catch (Throwable e) {
getEngineLog().error(e.toString(), e);
}
}
}
/**
* process tasks in execute engine.
*/
protected void processTasks() {
// 获取 task 中所有的数据,进行遍历
Collection<Object> keys = getAllTaskKeys();
for (Object taskKey : keys) {
// 移除的同时,会从之前 task map 中取对应的同步任务,removeTask的逻辑为:判断task是否为null && 是否需要被执行
// 如果判断通过 则直接调用tasks.remove(key)即concurrentHashMap自带的那个remove方法,删除且返回对应的value 即现在接收的AbstractDelayTask task,且这个方法内部使用了 ReentrantLock 的lock 和 unlock全程加锁保证线程安全
AbstractDelayTask task = removeTask(taskKey);
if (null == task) {
continue;
}
// 根据 taskey 获取 Nacos 操作对象
NacosTaskProcessor processor = getProcessor(taskKey);
if (null == processor) {
getEngineLog().error("processor not found for task, so discarded. " + task);
continue;
}
try {
// 把 task 任务放入到 第二层队列中去
if (!processor.process(task)) {
// 如果失败了,会重试同步
retryFailedTask(taskKey, task);
}
} catch (Throwable e) {
getEngineLog().error("Nacos task execute error : " + e.toString(), e);
retryFailedTask(taskKey, task);
}
}
}
我们继续回到DistroDelayTaskProcessor中,可以看到后续的内容是将然后封装为DistroSyncChangeTask类型的任务,然后通过DistroTaskEngineHolder的成员DistroExecuteTaskExecuteEngine的addTask方法添加到队列中
DistroExecuteTaskExecuteEngine的addTask方法逻辑如下(该方法在DistroExecuteTaskExecuteEngine的父类中继承而来 没有重写 要到其父类中查找)
public void addTask(Object tag, AbstractExecuteTask task) {
NacosTaskProcessor processor = getProcessor(tag);
if (null != processor) {
processor.process(task);
return;
}
TaskExecuteWorker worker = getWorker(tag);
// 把任务放入到 队列当中去
worker.process(task);
}
public boolean process(NacosTask task) {
if (task instanceof AbstractExecuteTask) {
// 放入到队列中
putTask((Runnable) task);
}
return true;
}
// 任务存储容器
private final BlockingQueue<Runnable> queue;
private void putTask(Runnable task) {
try {
// 放入到队列
queue.put(task);
} catch (InterruptedException ire) {
log.error(ire.toString(), ire);
}
}
这一块整体的源码逻辑是,从第一层内存队列把任务取出来,然后放入到第二层的BlockingQueue内存队列中。那么既然最后放入到了第二层队列BlockingQueue中,那么肯定也有个异步任务从这个queue中拿任务进行消费。很明显,这个消费的地方只有如下这一个地方,是处于TaskExecuteWorker下的InnerWorker这个Runable对象
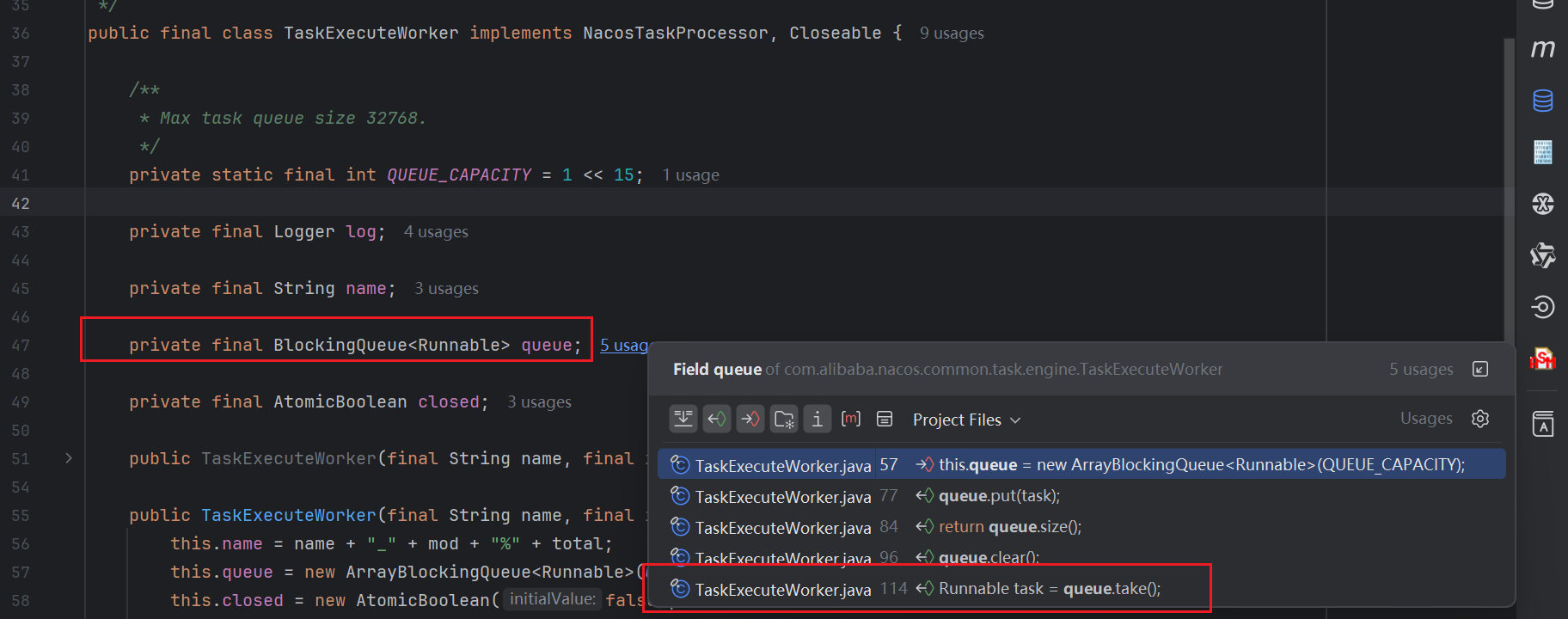
InnerWorker的run方法逻辑如下,很明显其逻辑就是从queue中直接take获取任务,然后调用其run方法进行执行,其任务类型就是DistroSyncChangeTask
/**
* Inner execute worker.
*/
private class InnerWorker extends Thread {
InnerWorker(String name) {
setDaemon(false);
setName(name);
}
public void run() {
while (!closed.get()) {
try {
// 一直取队列中的任务,这里的 task 任务类型是:DistroSyncChangeTask
Runnable task = queue.take();
long begin = System.currentTimeMillis();
// 调用 DistroSyncChangeTask 中的 run 方法
task.run();
long duration = System.currentTimeMillis() - begin;
if (duration > 1000L) {
log.warn("distro task {} takes {}ms", task, duration);
}
} catch (Throwable e) {
log.error("[DISTRO-FAILED] " + e.toString(), e);
}
}
}
}
DistroSyncChangeTask的逻辑如下,通过源码得知,最终还是通过 HTTP 的方式进行数据同步的,请求路径为/v1/ns/distro/datum
public void run() {
Loggers.DISTRO.info("[DISTRO-START] {}", toString());
try {
// 构建请求参数
String type = getDistroKey().getResourceType();
DistroData distroData = distroComponentHolder.findDataStorage(type).getDistroData(getDistroKey());
distroData.setType(DataOperation.CHANGE);
// syncData Http 的方式,同步数据
boolean result = distroComponentHolder.findTransportAgent(type).syncData(distroData, getDistroKey().getTargetServer());
if (!result) {
// 重试
handleFailedTask();
}
Loggers.DISTRO.info("[DISTRO-END] {} result: {}", toString(), result);
} catch (Exception e) {
Loggers.DISTRO.warn("[DISTRO] Sync data change failed.", e);
handleFailedTask();
}
}
public boolean syncData(DistroData data, String targetServer) {
if (!memberManager.hasMember(targetServer)) {
return true;
}
byte[] dataContent = data.getContent();
// 通过 http 同步新增节点数据
return NamingProxy.syncData(dataContent, data.getDistroKey().getTargetServer());
}
public static boolean syncData(byte[] data, String curServer) {
Map<String, String> headers = new HashMap<>(128);
headers.put(HttpHeaderConsts.CLIENT_VERSION_HEADER, VersionUtils.version);
headers.put(HttpHeaderConsts.USER_AGENT_HEADER, UtilsAndCommons.SERVER_VERSION);
headers.put(HttpHeaderConsts.ACCEPT_ENCODING, "gzip,deflate,sdch");
headers.put(HttpHeaderConsts.CONNECTION, "Keep-Alive");
headers.put(HttpHeaderConsts.CONTENT_ENCODING, "gzip");
try {
// 通过 http 同步数据 :/v1/ns/distro/datum
RestResult<String> result = HttpClient.httpPutLarge(
"http://" + curServer + EnvUtil.getContextPath() + UtilsAndCommons.NACOS_NAMING_CONTEXT
+ DATA_ON_SYNC_URL, headers, data);
if (result.ok()) {
return true;
}
if (HttpURLConnection.HTTP_NOT_MODIFIED == result.getCode()) {
return true;
}
throw new IOException("failed to req API:" + "http://" + curServer + EnvUtil.getContextPath()
+ UtilsAndCommons.NACOS_NAMING_CONTEXT + DATA_ON_SYNC_URL + ". code:" + result.getCode() + " msg: "
+ result.getData());
} catch (Exception e) {
Loggers.SRV_LOG.warn("NamingProxy", e);
}
return false;
}
别的节点对于同步请求的处理
已经知道是通过HTTP请求进行数据同步的且知道请求路径,那么直接可以去对应的Controller查看逻辑,其核心部分就在于onReceive
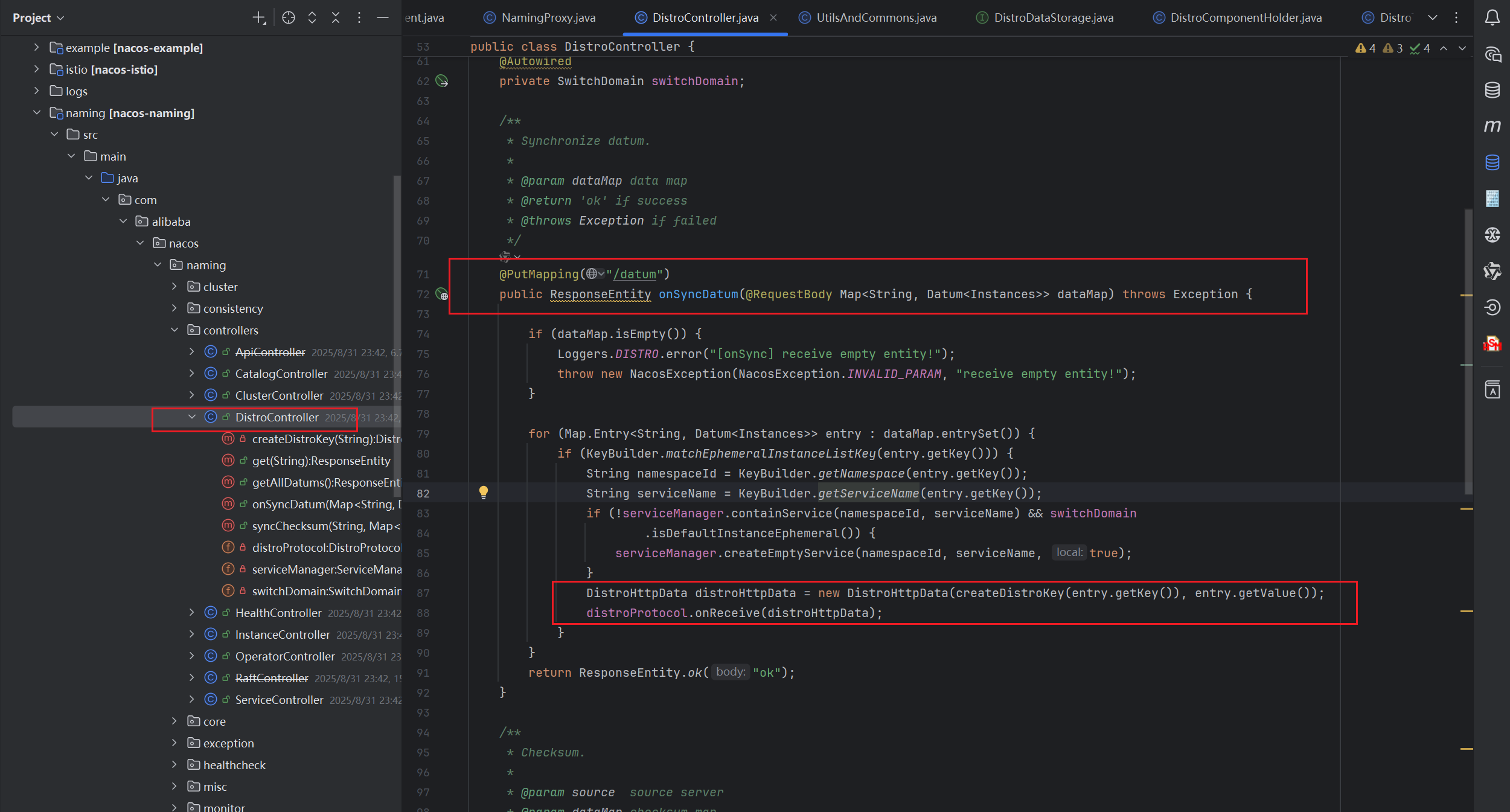
onReceive方法的逻辑如下
public boolean onReceive(DistroData distroData) {
String resourceType = distroData.getDistroKey().getResourceType();
DistroDataProcessor dataProcessor = distroComponentHolder.findDataProcessor(resourceType);
if (null == dataProcessor) {
Loggers.DISTRO.warn("[DISTRO] Can't find data process for received data {}", resourceType);
return false;
}
// 操作新增实例
return dataProcessor.processData(distroData);
}
public boolean processData(DistroData distroData) {
DistroHttpData distroHttpData = (DistroHttpData) distroData;
Datum<Instances> datum = (Datum<Instances>) distroHttpData.getDeserializedContent();
// 这里的 onPut 的方法就和实例注册中的 onPut 方法一致的 这个之前就解析过了
onPut(datum.key, datum.value);
return true;
}
总结
Nacos 集群中新增实例的跨节点同步逻辑,核心是通过 “双层内存队列 + 异步任务” 实现异步化、高可靠的数据同步。我们可以按 “触发同步→第一层队列处理→第二层队列处理→执行同步” 四个阶段拆解整个链路。
-
第一层(ConcurrentHashMap + 定时任务):作为 “缓冲层”,解决瞬时大量注册请求的削峰问题,通过延迟调度避免同步风暴,同时提供失败重试机制(任务可重新放入 Map)。
-
第二层(BlockingQueue + 异步线程):作为 “执行层”,保证任务有序执行(阻塞队列的 FIFO 特性),通过独立线程池隔离同步操作,避免影响主流程。
文章标题:Nacos源码学习计划-Day09-集群-新增微服务实例
文章链接:https://zealsinger.xyz/?post=34
本站所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议,转载请注明来自ZealSinger !
如果觉得文章对您有用,请随意打赏。
您的支持是我们继续创作的动力!

微信扫一扫

支付宝扫一扫
