Nacos源码学习计划-Day10-集群-集群节点健康状态变更数据同步
ZealSinger 发布于 阅读:225 技术文档
// 元数据结构如下
{
// 最后刷新时间
"lastRefreshTime": 1674093895774,
// raft 元信息
"raftMetaData": {
"metaDataMap": {
"naming_persistent_service": {
// leader IP 地址
"leader": "10.0.16.3:7849",
// raft 分组节点
"raftGroupMember": [
"10.0.16.3:7850",
"10.0.16.3:7848",
"10.0.16.3:7849"
],
"term": 1
}
}
},
// raft 端口
"raftPort": "7849",
// Nacos 版本
"version": "1.4.1"
}
可以看到节点的状态有up也有down
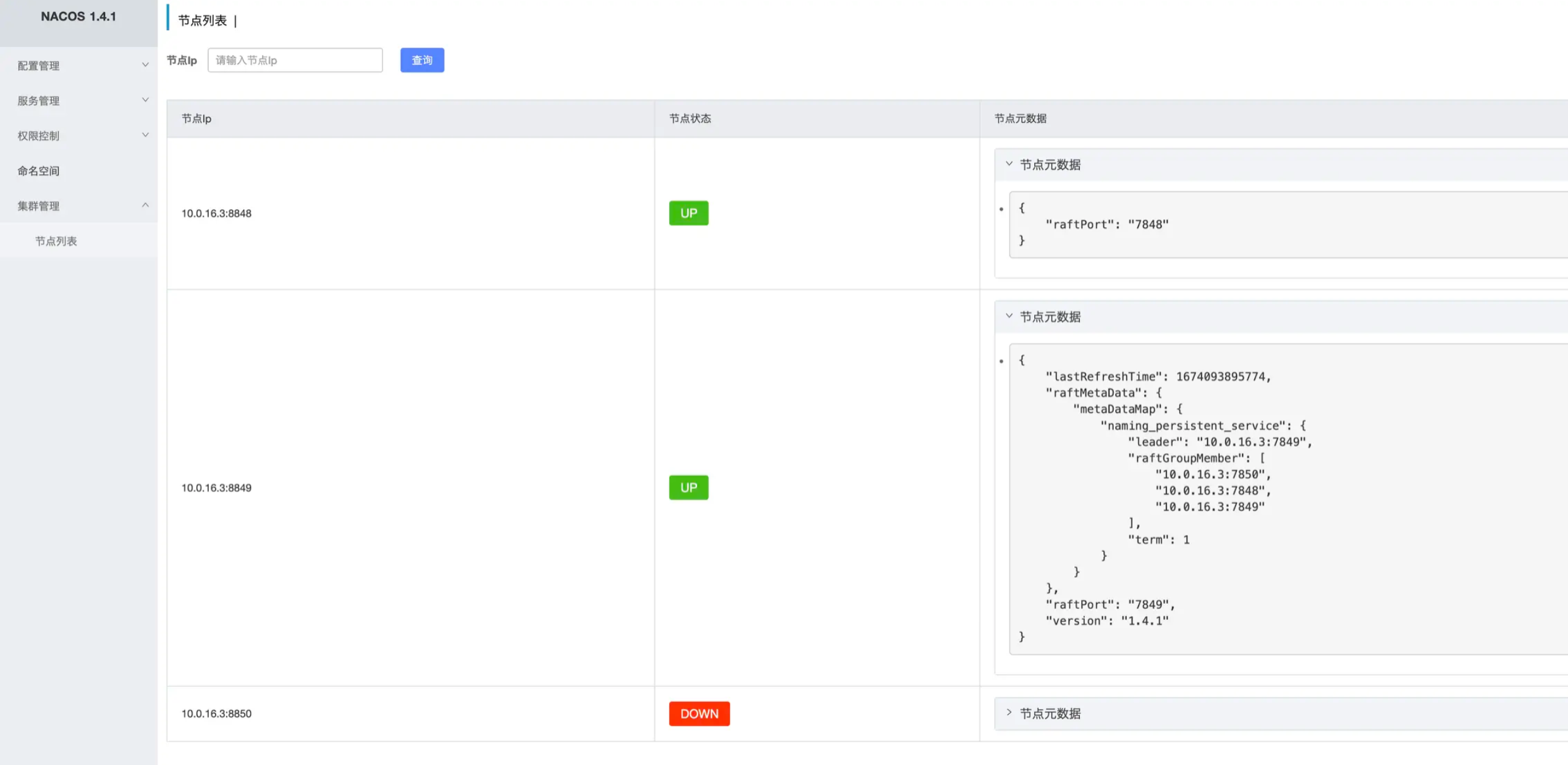
可以看到,集群管理中有很多和节点信息相关的内容,我们首先要来看的就是在集群之间节点状态 Nacos 是怎么维护的,其中某一台节点下线了,其他节点又是怎么感知的并且把状态修改成 DOWN的
集群节点健康状态变动数据同步
找到主线
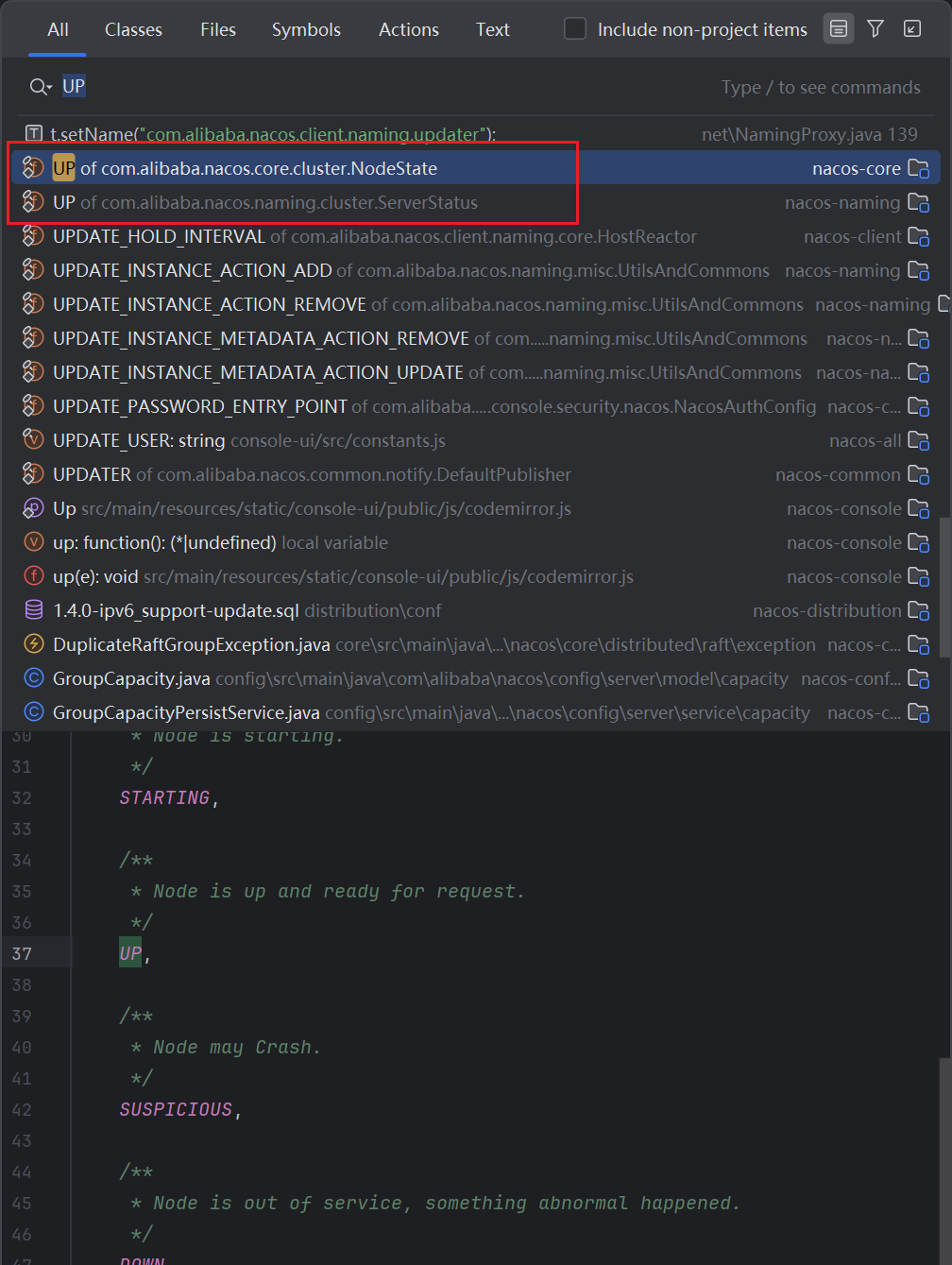
首先得找到相关的集群节点健康状态变化的时候才能找到对应的节点数据同步的地方,我们可以猜测到,内部服务肯定是使用了UP,Down,ServerStatus,NodeStatus这种枚举类,枚举成员进行记录的,那么利用IDEA的查询功能,我们去看看对应的内容
虽然比较多,但是还是能找到,ServerStatus和NodeStatus有这么两个枚举类,然后我们都去看看,可以发现应该是NodeStatus,ServerStatus是我们之前看的服务实例的状态
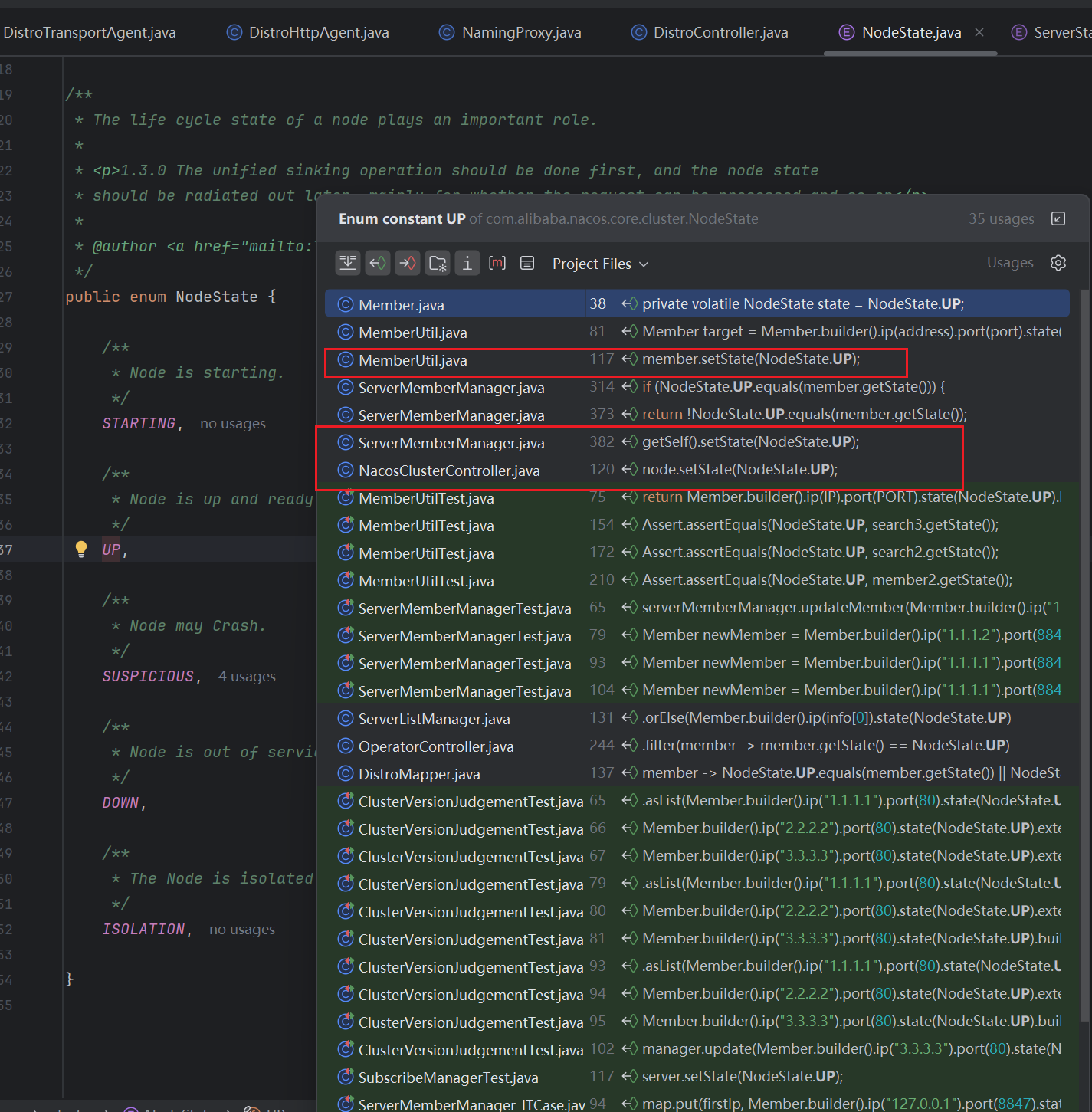
然后我们再查看UP这个枚举状态被使用的地方,因为是一个状态,肯定大多数用来设置状态或者比较状态,我们可以比较直接的看到MemberUtil,ServerMemberManager,NacosClusterController这三个中有比较明显的设置状态的动作,ServerMemberManager我们之前有过接触,这个是和服务实例有关的,所以这里我们优先看另外两个
可以看到,MemberUtil中调用UP状态的地方是一个onSuccess方法,从这个方法的逻辑就能看出来,这个就是我们要找的健康状态同步。(入参为Member,即代表和集群节点有关,会获取入参member的旧状态old,然后对于入参member的状态进行修改,再和old对比,如果对比不一样则会触发notifyMemberChange 从这个方法名也可以看出来是通知成员状态变化的方法)
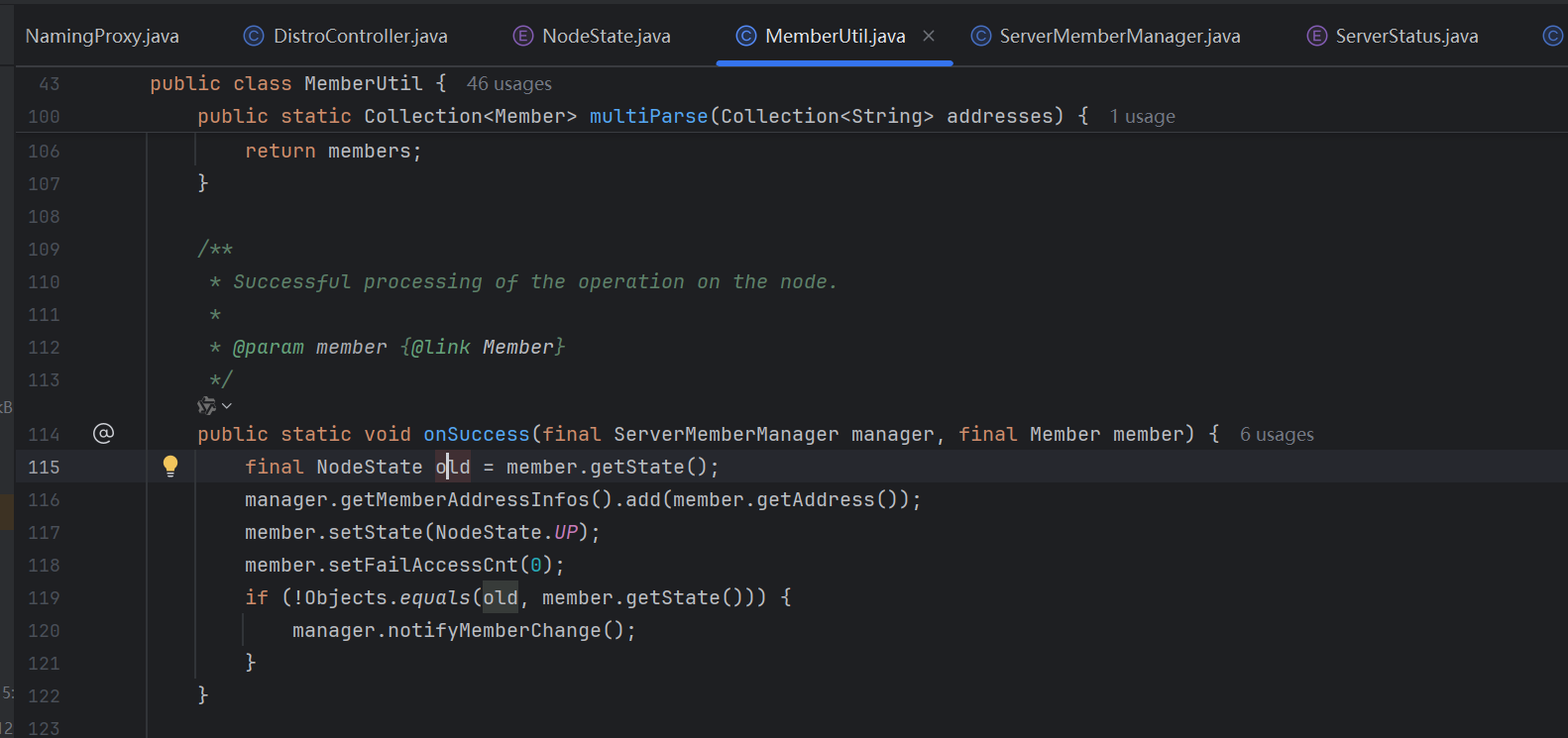
// 如果再要看一下NacosClusterController,可以看到这个是一个HTTP请求的处理接口,而且上面也有注释为“其他节点返回自己的元信息” 可以猜测和看出来,这个接口是和元数据同步功能相关,和健康状态的同步或许有关联,可能是健康状态封装在元数据内,然后节点之间通过HTTP请求进行的同步,这个逻辑也是有可能的,但是即使是这个情况,这个地方也是属于 “其余节点如何处理 同步节点状态”,是我们后面要来分析的,我们当前是为了找“从哪个地方触发的同步逻辑”
/**
* Other nodes return their own metadata information.
*
* @param node {@link Member}
* @return {@link RestResult}
*/
(value = {"/report"})
public RestResult<String> report( Member node) {
if (!node.check()) {
return RestResultUtils.failedWithMsg(400, "Node information is illegal");
}
LoggerUtils.printIfDebugEnabled(Loggers.CLUSTER, "node state report, receive info : {}", node);
node.setState(NodeState.UP);
node.setFailAccessCnt(0);
boolean result = memberManager.update(node);
return RestResultUtils.success(Boolean.toString(result));
}
分析主线
从onSuccess方法往上层看,就能发现来到了MemberInfoReportTask这个异步任务类,这里的代码设计思路就是抽象模板方法设计模式
/*
MemberInfoReportTask继承自Task这个抽象类,Task类是Nacos中自己定义的,实现了Runable接口的,专门作为任务类的抽象基类。
其内部逻辑很简单 如下,即规范了Nacos中所有的Task任务的执行规范和异常捕获,抽象方法executeBody就是任务的逻辑,run中只是对任务执行的异常捕获处理做了统一的规范
*/
public abstract class Task implements Runnable {
protected volatile boolean shutdown = false;
public void run() {
if (shutdown) {
return;
}
try {
executeBody();
} catch (Throwable t) {
Loggers.CORE.error("this task execute has error : {}", ExceptionUtil.getStackTrace(t));
} finally {
if (!shutdown) {
after();
}
}
}
/**
* Task executive.
*/
protected abstract void executeBody();
/**
* after executeBody should do.
*/
protected void after() {
}
public void shutdown() {
shutdown = true;
}
}
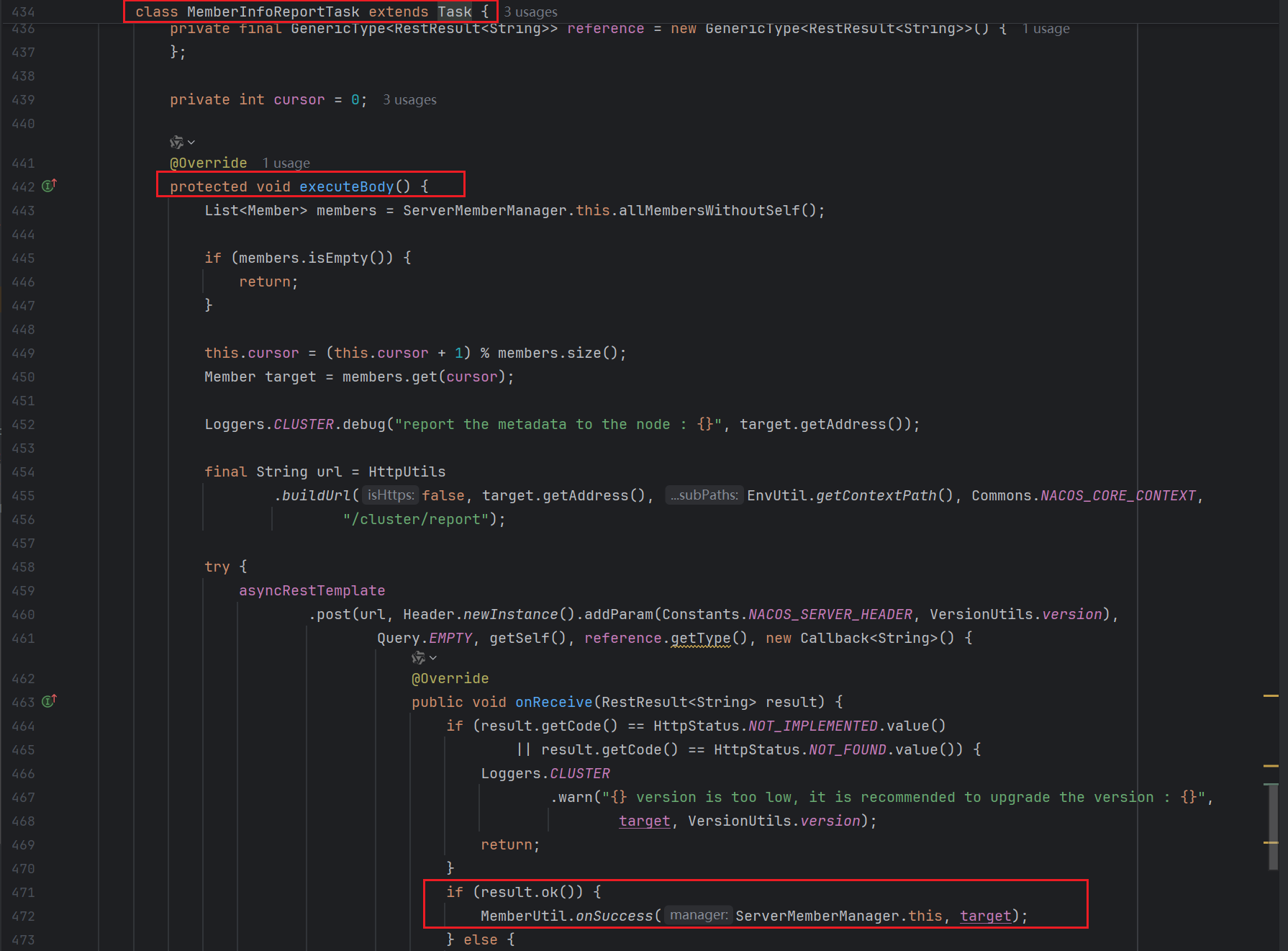
既然知道了健康状态同步是一个异步任务,那么我们就可以来看看哪个地方开启的这个异步任务
MemberInfoReportTask任务对象在ServerMemberManager这个了类中作为成员被创建,同时又在ServerMemberManager中的onApplicationEvetn方法中利用GlobaExecutor全局线程池,定时每隔5000ms执行任务(这里底层是线程池类型是的ScheduledThreadPool)。onApplicationEvent是实现ApplicationListener接口的方法,在Spring Bean容器初始化完成后执行触发
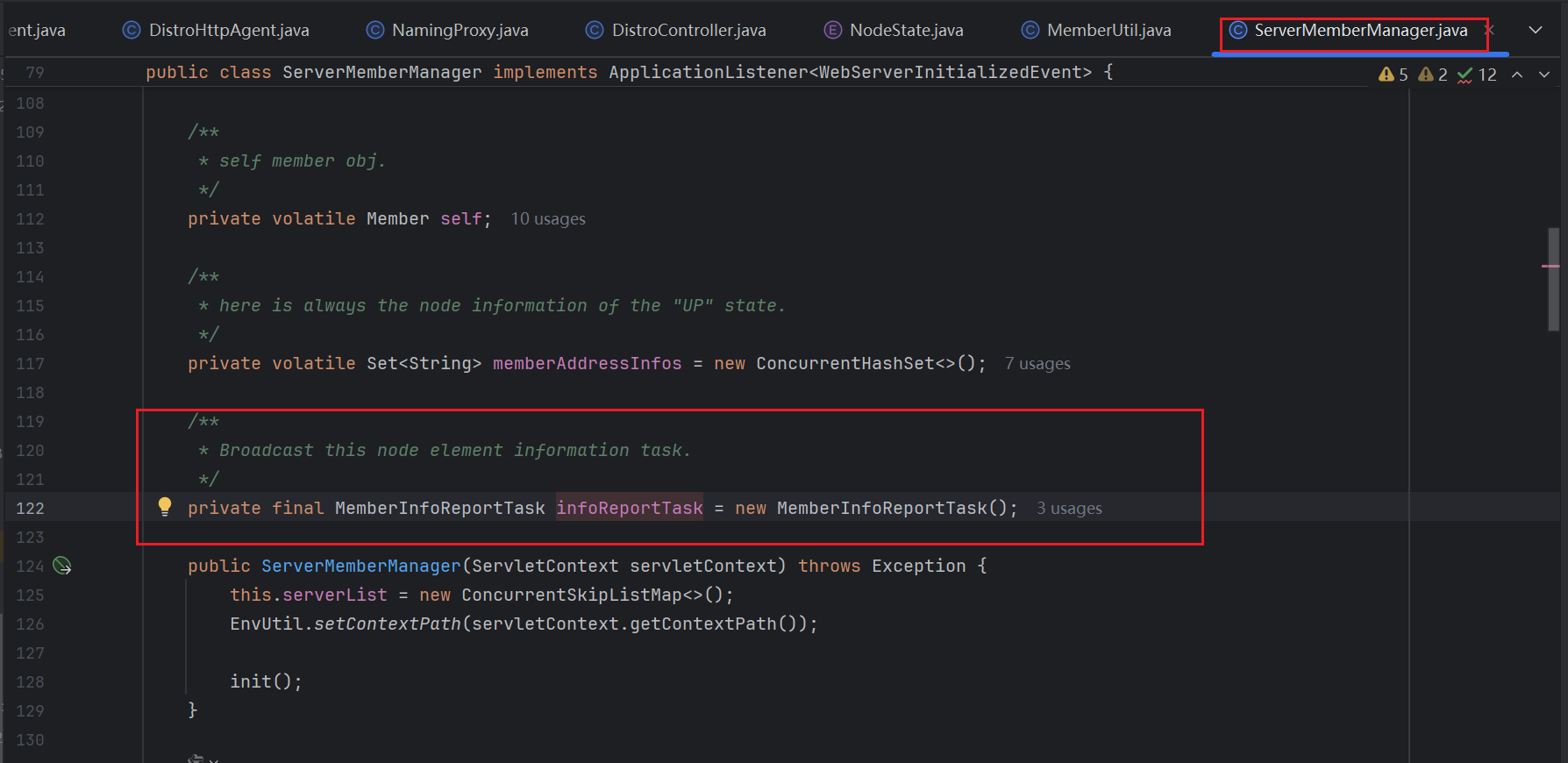
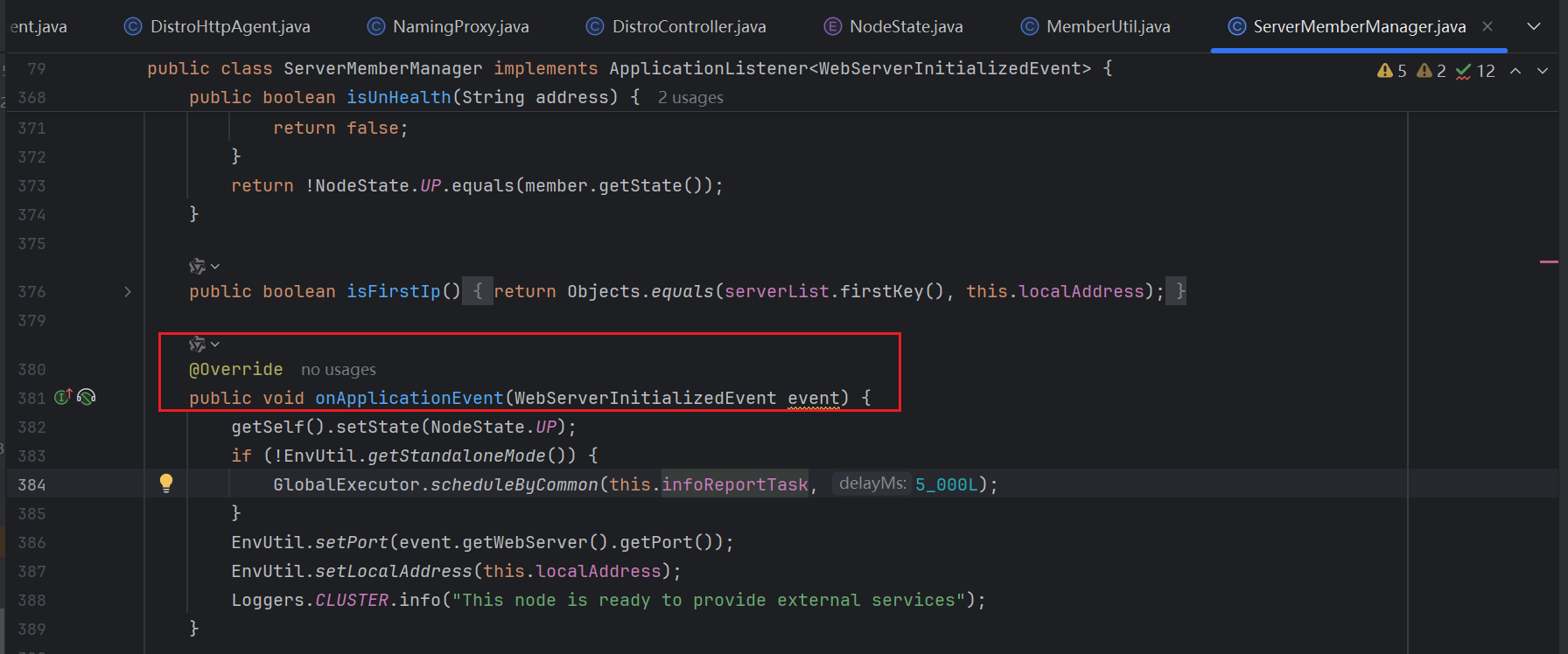
从上面知道,这个异步任务在Nacos启动的时候,就被放入到线程池中进行延迟的5000ms自动执行,也就是说Nacos中集群节点之间的健康状态是启动5000ms后自动维护和更新的
既然知道了异步任务的执行策略,现在就可以回过来看看这个异步任务的执行逻辑了
从这个代码逻辑中可以看到,逻辑主体为:方法一开始会获取除自身以外的集群节点,然后通过轮询算法选举出本次请求的目标对象,最后通过 HTTP 的方式来请求目标节点,如果请求目标节点返回成功那么就会执行onSuccess()方法,如果失败了就会执行onFail()方法,并把目标节点的state属性修改为DOWN。本轮任务完成后最后在after逻辑中再次提交任务,延迟2000ms执行,也就是说完成第一次异步任务之后,正常情况下是每2000ms进行一次节点健康状态的同步,且是轮询同步的(2000ms和与A节点HTTP通讯然后对比状态字段,再过2000ms与B进行HTTP通信然后对比状态字段)
class MemberInfoReportTask extends Task {
private final GenericType<RestResult<String>> reference = new GenericType<RestResult<String>>() {
};
private int cursor = 0;
protected void executeBody() {
List<Member> members = ServerMemberManager.this.allMembersWithoutSelf();
if (members.isEmpty()) {
return;
}
this.cursor = (this.cursor + 1) % members.size();
Member target = members.get(cursor);
Loggers.CLUSTER.debug("report the metadata to the node : {}", target.getAddress());
final String url = HttpUtils
.buildUrl(false, target.getAddress(), EnvUtil.getContextPath(), Commons.NACOS_CORE_CONTEXT,
"/cluster/report");
try {
asyncRestTemplate
.post(url, Header.newInstance().addParam(Constants.NACOS_SERVER_HEADER, VersionUtils.version),
Query.EMPTY, getSelf(), reference.getType(), new Callback<String>() {
public void onReceive(RestResult<String> result) {
if (result.getCode() == HttpStatus.NOT_IMPLEMENTED.value()
|| result.getCode() == HttpStatus.NOT_FOUND.value()) {
Loggers.CLUSTER
.warn("{} version is too low, it is recommended to upgrade the version : {}",
target, VersionUtils.version);
return;
}
if (result.ok()) {
MemberUtil.onSuccess(ServerMemberManager.this, target);
} else {
Loggers.CLUSTER
.warn("failed to report new info to target node : {}, result : {}",
target.getAddress(), result);
MemberUtil.onFail(ServerMemberManager.this, target);
}
}
public void onError(Throwable throwable) {
Loggers.CLUSTER
.error("failed to report new info to target node : {}, error : {}",
target.getAddress(),
ExceptionUtil.getAllExceptionMsg(throwable));
MemberUtil.onFail(ServerMemberManager.this, target, throwable);
}
public void onCancel() {
}
});
} catch (Throwable ex) {
Loggers.CLUSTER.error("failed to report new info to target node : {}, error : {}", target.getAddress(),
ExceptionUtil.getAllExceptionMsg(ex));
}
}
protected void after() {
GlobalExecutor.scheduleByCommon(this, 2_000L);
}
}
OK,这边弄清楚了之后,我们看看这个HTTP请求打到Nacos集群中别的节点中会如何被处理,继续通过URL找到对应的Controller
(value = {"/report"})
public RestResult<String> report( Member node) {
if (!node.check()) {
return RestResultUtils.failedWithMsg(400, "Node information is illegal");
}
LoggerUtils.printIfDebugEnabled(Loggers.CLUSTER, "node state report, receive info : {}", node);
// 能够正常发起这个请求的节点 即入参 肯定是健康的 所以直接设置为UP存活状态
node.setState(NodeState.UP);
node.setFailAccessCnt(0);
boolean result = memberManager.update(node);
return RestResultUtils.success(Boolean.toString(result));
}
可以看到核心方法在update方法,查看update方法的源码
这里核心逻辑主要是把之前存放在 serverList 中对应的属性进行更新,通过MemberUtil.copy把老对象的属性进行更新,这个流程就结束了。在这里说一下,serverList 属性是在每一个集群节点中都有一份,所以需要对本地的serverList 属性中的节点进行数据更新
public boolean update(Member newMember) {
Loggers.CLUSTER.debug("member information update : {}", newMember);
String address = newMember.getAddress();
if (!serverList.containsKey(address)) {
return false;
}
serverList.computeIfPresent(address, (s, member) -> {
// 如果服务状态不健康,则直接移除,在这里不是主要的逻辑
if (NodeState.DOWN.equals(newMember.getState())) {
memberAddressInfos.remove(newMember.getAddress());
}
// 比对信息是否有做改变
boolean isPublishChangeEvent = MemberUtil.isBasicInfoChanged(newMember, member);
// 修改 lastRefreshTime 设置为当前时间
newMember.setExtendVal(MemberMetaDataConstants.LAST_REFRESH_TIME, System.currentTimeMillis());
// 属性覆盖,也可以说更新属性
MemberUtil.copy(newMember, member);
// 如果有做改变,需要发布相关事件通知 这里的notifyMemberChange和上面的onSuccess中的notifyMemberChange是一个方法,即通过事件通知的方式更新节点状态
if (isPublishChangeEvent) {
// member basic data changes and all listeners need to be notified
notifyMemberChange();
}
return member;
});
return true;
}
总结
-
Nacos集群中的节点健康状态数据同步,是由MemberInfoReportTask这个异步任务开启的
-
当Nacos服务启动之后,每个Nacos节点都会在启动5000ms后,开始轮询向除自己外的每个Nacos节点进行数据同步,这个过程是一个异步的HTTP请求实现
-
对应的目标节点接收到这个HTTP请求后,将发送请求的Nacos节点的状态更新为UP,和本地记录的该节点的状态进行对比,如果变化则返回false且发布一个Event事件修改本地集群节点健康状态记录列表,反之返回true
-
发起请求的Nacos根据返回值进行回调,如果返回的true,进入onSucces()逻辑,则说明目标Nacos节点是存活的,将其设置为UP并且和本地记录的该节点的状态进行对比,同上,如果变化则发布一个Event事件修改本地集群节点健康状态记录列表,没有变化则不会进行额外的操作,随后进行after()任务后处理操作,确保异步任务Task再次进入任务队列
-
如果请求无响应/错误响应/请求发生错误等情况,则打印日志进行记录后进入onFail()逻辑,在这个逻辑中会累积对应Member/Target的失败响应次数,当连接失败次数达到阈值(Nacos环境配置中可以设置最大允许次数)或者连接异常Exception中包含"Connection refused"(连接被拒绝)才会设置为DOWN即下线 ; 如果没有达到阈值或者没有对应的异常信息,则暂且只会被记录为SUSPICIOUS疑似下线
文章标题:Nacos源码学习计划-Day10-集群-集群节点健康状态变更数据同步
文章链接:https://zealsinger.xyz/?post=35
本站所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议,转载请注明来自ZealSinger !
如果觉得文章对您有用,请随意打赏。
您的支持是我们继续创作的动力!

微信扫一扫

支付宝扫一扫